|
|
@@ -1,483 +0,0 @@
|
|
|
-# !usr/bin/env python
|
|
|
-# -*- coding:utf-8 _*-
|
|
|
-"""
|
|
|
-@Author:Lijiaxing
|
|
|
-
|
|
|
-@File:data_analysis.py
|
|
|
-@Time:2023/4/24 15:16
|
|
|
-
|
|
|
-"""
|
|
|
-import os.path
|
|
|
-
|
|
|
-import pandas as pd
|
|
|
-# from mpl_toolkits.basemap import Basemap
|
|
|
-from scipy.signal import savgol_filter
|
|
|
-import numpy as np
|
|
|
-import matplotlib.pyplot as plt
|
|
|
-from scipy.cluster.hierarchy import dendrogram, linkage, fcluster
|
|
|
-from sklearn.metrics import silhouette_samples, silhouette_score
|
|
|
-
|
|
|
-def paint_others(y):
|
|
|
- """ 绘制其他数据 """
|
|
|
- plt.plot([j for j in range(y)], y)
|
|
|
- # 添加标题和标签
|
|
|
- plt.xlabel('x')
|
|
|
- plt.ylabel('y')
|
|
|
-
|
|
|
- # 显示图形
|
|
|
- plt.show()
|
|
|
-
|
|
|
-
|
|
|
-def compute_cos_similarity(a, b):
|
|
|
- """
|
|
|
- 计算两个向量的余弦相似度
|
|
|
- :param a: 向量a
|
|
|
- :param b: 向量b
|
|
|
- :return: 余弦相似度值
|
|
|
- """
|
|
|
- return np.dot(a, b) / (np.linalg.norm(a) * np.linalg.norm(b))
|
|
|
-
|
|
|
-
|
|
|
-def compute_pearsonr(a):
|
|
|
- """
|
|
|
- 计算数据皮尔逊相关系数并返回相似度矩阵
|
|
|
- :param a: 数据格式为n*m的矩阵,n为数据个数,m为数据维度
|
|
|
- :return: 返回相似度矩阵,数据格式为n*n的矩阵
|
|
|
- """
|
|
|
- return np.corrcoef(a)
|
|
|
-
|
|
|
-
|
|
|
-def compute_distance(a, b):
|
|
|
- """
|
|
|
- 计算两个向量的欧式距离
|
|
|
- :param a:
|
|
|
- :param b:
|
|
|
- :return: 返回两个向量的欧式距离
|
|
|
- """
|
|
|
- return np.linalg.norm(a - b)
|
|
|
-
|
|
|
-
|
|
|
-def hierarchical_clustering(data, threshold, similarity_func):
|
|
|
- """
|
|
|
- 层次聚类,使用工具包scipy.cluster.hierarchy中的linkage和fcluster函数进行层次聚类
|
|
|
- :param data: 二维数据,格式为n*m的矩阵,n为数据个数,m为数据维度
|
|
|
- :param threshold: 阈值,当两个数据的距离小于阈值时,将两个数据归为一类,阈值为根据相似度矩阵层次聚类后的类别距离阈值,可根据需求进行调整,可大于1
|
|
|
- :param similarity_func: 相似度计算函数,用于计算两个数据的相似度,可以进行替换,若替换为计算距离的函数需对内部进行修改
|
|
|
- :return: 返回聚类结果,格式为n*1的矩阵,n为数据个数,每个数据的值为该数据所属的类别
|
|
|
- """
|
|
|
- # 计算数据的相似度矩阵
|
|
|
- similarity_matrix = similarity_func(data)
|
|
|
-
|
|
|
- # 计算数据的距离矩阵
|
|
|
- distance_matrix = 1 - similarity_matrix
|
|
|
-
|
|
|
- # 进行层次聚类返回聚类结果
|
|
|
- Z = linkage(distance_matrix, method='ward')
|
|
|
- # 根据相似度阈值获取聚类结果
|
|
|
- clusters = fcluster(Z, t=threshold, criterion='distance')
|
|
|
- # 画出层次聚类树形结构
|
|
|
- fig = plt.figure(figsize=(5, 3))
|
|
|
- dn = dendrogram(Z)
|
|
|
- plt.show()
|
|
|
- # clusters[42] = 1
|
|
|
- silhouette = silhouette_samples(np.abs(distance_matrix), clusters, metric='euclidean')
|
|
|
- silhouette1 = silhouette_score(np.abs(distance_matrix), clusters, metric='euclidean')
|
|
|
- print(f"平均轮廓系数为:{silhouette1}, 单个样本的轮廓系数:{silhouette}")
|
|
|
- return clusters
|
|
|
-
|
|
|
-
|
|
|
-class DataAnalysis:
|
|
|
- """
|
|
|
- 数据分析类
|
|
|
- """
|
|
|
-
|
|
|
- def __init__(self, data_length, data_start, data_end):
|
|
|
- """
|
|
|
- 初始化
|
|
|
- :param data_length: 分析数据段长度
|
|
|
- :param data_start: 分析数据段开始位置
|
|
|
- :param data_end: 分析数据段结束位置
|
|
|
- """
|
|
|
- # 原始风机功率数据傅里叶变换滤波后的数据
|
|
|
- self.ori_turbine_fft = None
|
|
|
- # 原始风机功率数据片段
|
|
|
- self.ori_turbine_pic = None
|
|
|
- # 聚类结果
|
|
|
- self.cluster = None
|
|
|
- # 风机功率差分平滑后的结果
|
|
|
- self.smooth_turbine_diff = None
|
|
|
- # 风机功率差分变化情况
|
|
|
- self.diff_change = None
|
|
|
- # 风机功率差分
|
|
|
- self.turbine_diff = None
|
|
|
- # 全部风机数据
|
|
|
- self.turbine = None
|
|
|
- # 风机的标号顺序
|
|
|
- self.turbine_id = list(range(102, 162))
|
|
|
- # b1b4 = [142, 143, 144, 145]
|
|
|
- # self.turbine_id = [id for id in self.turbine_id if id not in b1b4]
|
|
|
- # 风机功率数据15分钟级别
|
|
|
- self.power_15min = None
|
|
|
- # 风机经纬度信息
|
|
|
- self.info = None
|
|
|
- # 使用数据长度
|
|
|
- self.data_length = data_length
|
|
|
- # 使用数据开始位置
|
|
|
- self.data_start = data_start
|
|
|
- # 使用数据结束位置
|
|
|
- self.data_end = data_end
|
|
|
- # 导入数据
|
|
|
- self.load_data(normalize=True)
|
|
|
- # 计算风机功率差分
|
|
|
- self.compute_turbine_diff()
|
|
|
-
|
|
|
- def load_data(self, normalize=False):
|
|
|
- """
|
|
|
- 加载数据
|
|
|
- :return:
|
|
|
- """
|
|
|
- self.info = pd.read_csv('../data-process/data/风机信息.csv', encoding='utf-8')
|
|
|
- # power_15min = pd.read_csv('../data/power_15min.csv')
|
|
|
- # for i in range(len(power_15min)):
|
|
|
- # if power_15min.loc[i, 'C_REAL_VALUE'] == -9999:
|
|
|
- # # 方便在曲线中看出缺失数据位置
|
|
|
- # power_15min.loc[i, 'C_REAL_VALUE'] = -34.56789
|
|
|
- # self.power_15min = power_15min
|
|
|
- turbine_path = '../data-process/data/output_filtered_csv_files/turbine-{}.csv'
|
|
|
- self.turbine, turbines = {}, []
|
|
|
- for i in self.turbine_id:
|
|
|
- self.turbine[i] = pd.read_csv(turbine_path.format(i))[20:].reset_index(drop=True)
|
|
|
- if normalize is True:
|
|
|
- self.normalize()
|
|
|
-
|
|
|
- def normalize(self):
|
|
|
- turbines = [self.turbine[i].values[:, 1:].astype(np.float32) for i in self.turbine_id]
|
|
|
- turbines = np.vstack(turbines)
|
|
|
- mean, std = np.mean(turbines, axis=0), np.std(turbines, axis=0)
|
|
|
- for i in self.turbine_id:
|
|
|
- c_time = self.turbine[i]['C_TIME']
|
|
|
- self.turbine[i] = (self.turbine[i].iloc[:, 1:] - mean) / std
|
|
|
- self.turbine[i].insert(loc=0, column='C_TIME', value=c_time)
|
|
|
- return self.turbine
|
|
|
-
|
|
|
- def compute_turbine_diff(self):
|
|
|
- """
|
|
|
- 计算风机功率差分
|
|
|
- :return:
|
|
|
- """
|
|
|
- turbine_diff = []
|
|
|
- ori_turbine_pic = []
|
|
|
- for turbine_i in self.turbine_id:
|
|
|
- ori = np.array(self.turbine[turbine_i]['C_WS'].values[self.data_start:self.data_end + 1])
|
|
|
- diff_array = np.diff(ori)
|
|
|
- smoothness_value = np.std(diff_array)
|
|
|
- print("turbine-{}的平滑度是:{}".format(turbine_i, round(smoothness_value, 2)))
|
|
|
- turbine_diff.append(diff_array)
|
|
|
- ori_turbine_pic.append(self.turbine[turbine_i]['C_WS'].values[self.data_start:self.data_end])
|
|
|
- self.ori_turbine_pic = ori_turbine_pic
|
|
|
- self.turbine_diff = turbine_diff
|
|
|
-
|
|
|
- diff_change = []
|
|
|
- for diff_i in turbine_diff:
|
|
|
- single_diff_change = []
|
|
|
- for diff_i_i in diff_i:
|
|
|
- if diff_i_i > 0:
|
|
|
- single_diff_change.append(1)
|
|
|
- elif diff_i_i < 0:
|
|
|
- single_diff_change.append(-1)
|
|
|
- else:
|
|
|
- single_diff_change.append(0)
|
|
|
- diff_change.append(single_diff_change)
|
|
|
- self.diff_change = diff_change
|
|
|
- self.ori_turbine_fft = [self.turbine_fft(i + 1) for i in range(len(self.ori_turbine_pic))]
|
|
|
-
|
|
|
- # 平滑
|
|
|
- self.turbine_smooth(window_size=21)
|
|
|
-
|
|
|
- def paint_map(self):
|
|
|
- """
|
|
|
- 绘制经纬度地图
|
|
|
- :return:
|
|
|
- """
|
|
|
- lats = self.info['纬度'].values
|
|
|
- lons = self.info['经度'].values
|
|
|
- map = Basemap()
|
|
|
-
|
|
|
- # 绘制海岸线和国家边界
|
|
|
- map.drawcoastlines()
|
|
|
- map.drawcountries()
|
|
|
-
|
|
|
- # 绘制经纬度坐标
|
|
|
- map.drawmeridians(range(0, 360, 30))
|
|
|
- map.drawparallels(range(-90, 90, 30))
|
|
|
-
|
|
|
- # 绘制点
|
|
|
-
|
|
|
- x, y = map(lons, lats)
|
|
|
- map.plot(x, y, 'bo', markersize=10)
|
|
|
-
|
|
|
- # 显示图表
|
|
|
- plt.show()
|
|
|
-
|
|
|
- def paint_power15min(self):
|
|
|
- """
|
|
|
- 绘制15分钟功率曲线
|
|
|
- :return:
|
|
|
- """
|
|
|
-
|
|
|
- plt.plot(self.power_15min['C_REAL_VALUE'])
|
|
|
-
|
|
|
- # 设置图表标题和轴标签
|
|
|
- plt.title('Data Time Change Curve')
|
|
|
- plt.xlabel('Date')
|
|
|
- plt.ylabel('Value')
|
|
|
-
|
|
|
- # 显示图表
|
|
|
- plt.show()
|
|
|
-
|
|
|
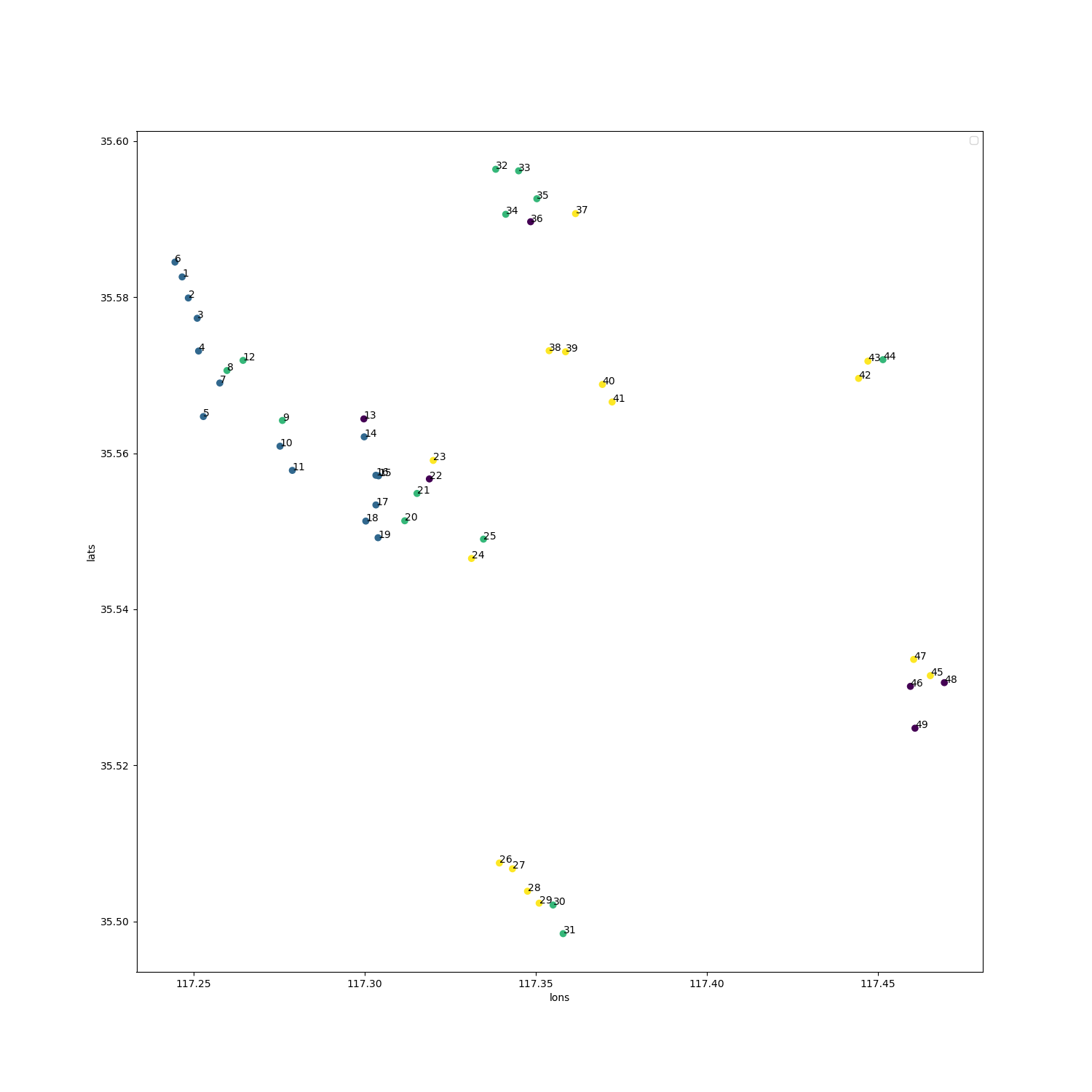
- def paint_lats_lons(self):
|
|
|
- """
|
|
|
- 绘制经纬度图
|
|
|
- :return:
|
|
|
- """
|
|
|
- x = self.info['纬度'].values
|
|
|
- y = self.info['经度'].values
|
|
|
-
|
|
|
- # 绘制散点图
|
|
|
- fig, ax = plt.subplots()
|
|
|
- plt.scatter(x, y)
|
|
|
-
|
|
|
- for i, txt in enumerate(self.info['id'].values):
|
|
|
- ax.annotate(txt, (x[i], y[i]))
|
|
|
-
|
|
|
- # 设置图表标题和轴标签
|
|
|
- plt.xlabel('lats')
|
|
|
- plt.ylabel('lons')
|
|
|
-
|
|
|
- # 显示图表
|
|
|
- plt.show()
|
|
|
-
|
|
|
- def similarity_score(self, turbine_diff, threshold=0.5):
|
|
|
- """
|
|
|
- 使用余弦相似度计算相似度分数并返回相似度大于阈值的index矩阵
|
|
|
- :param turbine_diff: 需要计算相似的矩阵,数据格式n*m,n为数据条数,m为数据维数
|
|
|
- :param threshold: 相似度阈值
|
|
|
- :return: 返回相似计算后的矩阵
|
|
|
- """
|
|
|
- similarity = {i: [] for i in range(49)}
|
|
|
- similarity_index = {i: [] for i in range(49)}
|
|
|
- for turbine_i in range(49):
|
|
|
- for turbine_j in range(49):
|
|
|
- cos_similarity = compute_cos_similarity(turbine_diff[turbine_i], turbine_diff[turbine_j])
|
|
|
- similarity[turbine_i].append(cos_similarity)
|
|
|
- if cos_similarity > threshold:
|
|
|
- similarity_index[turbine_i].append(turbine_j)
|
|
|
- return similarity_index
|
|
|
-
|
|
|
- def paint_turbine(self, paint_default=True):
|
|
|
- """
|
|
|
- 绘制风机地理位置图
|
|
|
- :param paint_default:默认True,绘制聚类后每个类别的数据折线图
|
|
|
- :return: None
|
|
|
- """
|
|
|
-
|
|
|
- # y = self.info['纬度'].values
|
|
|
- # x = self.info['经度'].values
|
|
|
- #
|
|
|
- # fig, ax = plt.subplots(figsize=(15, 15))
|
|
|
- #
|
|
|
- # plt.scatter(x, y, c=self.cluster)
|
|
|
- # for i, txt in enumerate(self.info['C_ID'].values):
|
|
|
- # ax.annotate(txt, (x[i], y[i]))
|
|
|
-
|
|
|
- # 设置图表标题和轴标签
|
|
|
- # plt.xlabel('lons')
|
|
|
- # plt.ylabel('lats')
|
|
|
- # plt.legend()
|
|
|
- #
|
|
|
- # # 显示图表
|
|
|
- # plt.savefig('analysis_img/turbine_cluster.png')
|
|
|
- # plt.show()
|
|
|
-
|
|
|
- plt.figure(figsize=(20, 10))
|
|
|
- cmap = plt.get_cmap('viridis')
|
|
|
- linestyle= ['solid', 'dashed']
|
|
|
- for i in range(max(self.cluster)):
|
|
|
- cluster, cluster_fft = [], []
|
|
|
- for j, item in enumerate(self.cluster):
|
|
|
- if item == i + 1:
|
|
|
- cluster.append(self.ori_turbine_pic[j])
|
|
|
- cluster_fft.append(self.ori_turbine_fft[j])
|
|
|
- cluster_fft = np.average(cluster_fft, axis=0)
|
|
|
- cluster = np.average(cluster, axis=0)
|
|
|
- diff_array = np.diff(cluster)
|
|
|
- smoothness_value = np.std(diff_array)
|
|
|
- print("聚类-{}的平滑度是:{}".format(i+1, smoothness_value))
|
|
|
- color = cmap(i*200)
|
|
|
- plt.subplot(2, 1, 1)
|
|
|
- plt.plot([j for j in range(len(cluster))], cluster, color=color, label='cluster'+str(i), linestyle=linestyle[i])
|
|
|
- plt.subplot(2, 1, 2)
|
|
|
- plt.plot([j for j in range(len(cluster_fft))], cluster_fft, color=color, label='cluster'+str(i), linestyle=linestyle[i])
|
|
|
-
|
|
|
- # 添加图例
|
|
|
- plt.legend()
|
|
|
- # 显示图形
|
|
|
- plt.savefig('analysis_img/cluster/clusters.png')
|
|
|
- plt.show()
|
|
|
- if paint_default:
|
|
|
- for i in range(max(self.cluster)):
|
|
|
- self.paint_turbine_k(i + 1) # 画出聚类中每个风机的曲线
|
|
|
-
|
|
|
-
|
|
|
-
|
|
|
- def turbine_smooth(self, window_size=50):
|
|
|
- """
|
|
|
- 使用滑动平均平滑数据。
|
|
|
-
|
|
|
- 参数:
|
|
|
- data -- 需要平滑的数据,numpy数组类型
|
|
|
- window_size -- 滑动窗口大小,整数类型
|
|
|
-
|
|
|
- 返回值:
|
|
|
- smooth_data -- 平滑后的数据,numpy数组类型
|
|
|
- """
|
|
|
-
|
|
|
- # weights = np.repeat(1.0, window_size) / window_size
|
|
|
- smooth_data = []
|
|
|
- for turbine_diff_i in self.turbine_diff:
|
|
|
- smooth_y = savgol_filter(turbine_diff_i, window_length=window_size, polyorder=3)
|
|
|
- smooth_data.append(smooth_y)
|
|
|
- # smooth_data.append(np.convolve(turbine_diff_i, weights, 'valid'))
|
|
|
- self.smooth_turbine_diff = smooth_data
|
|
|
-
|
|
|
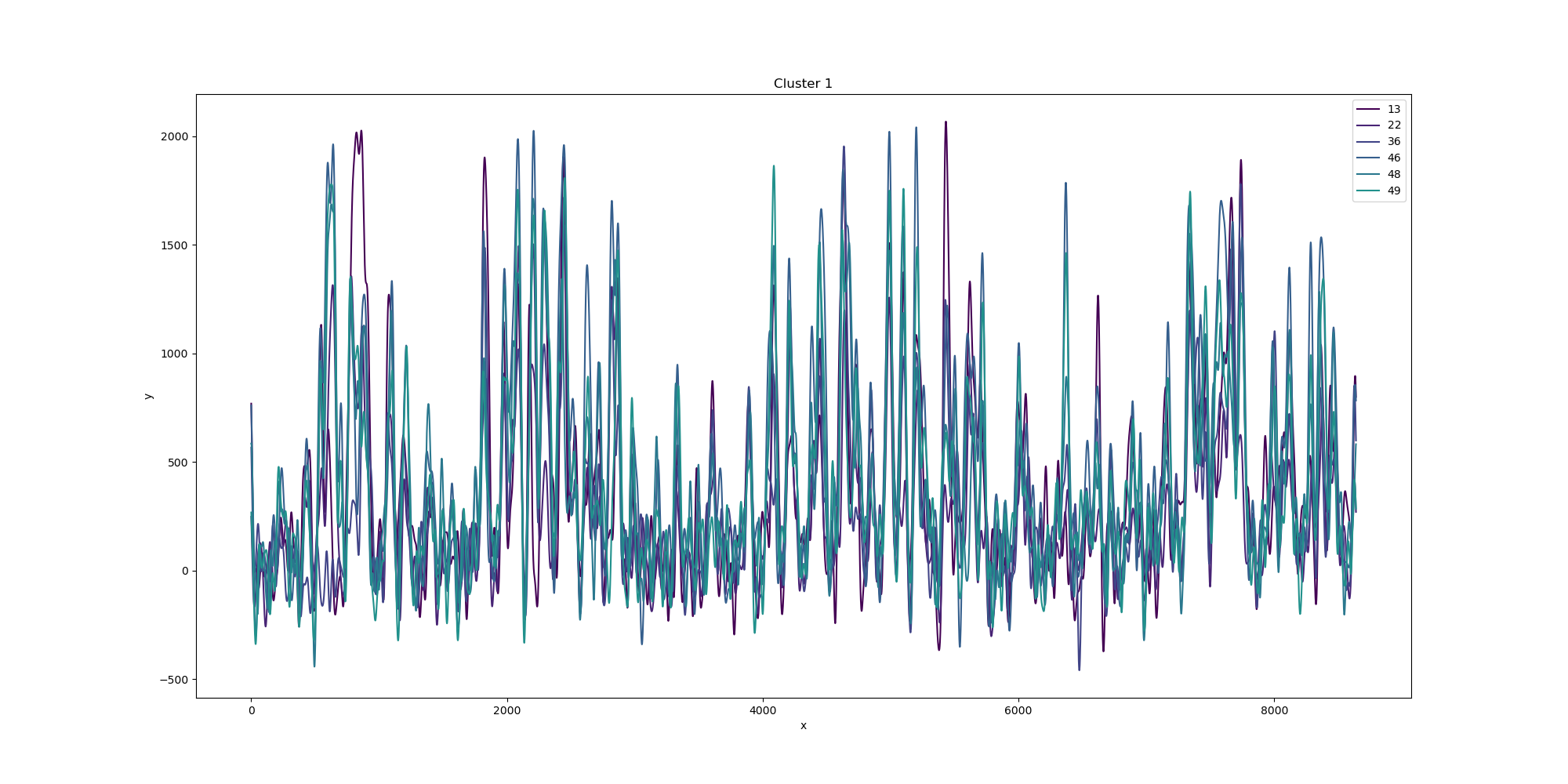
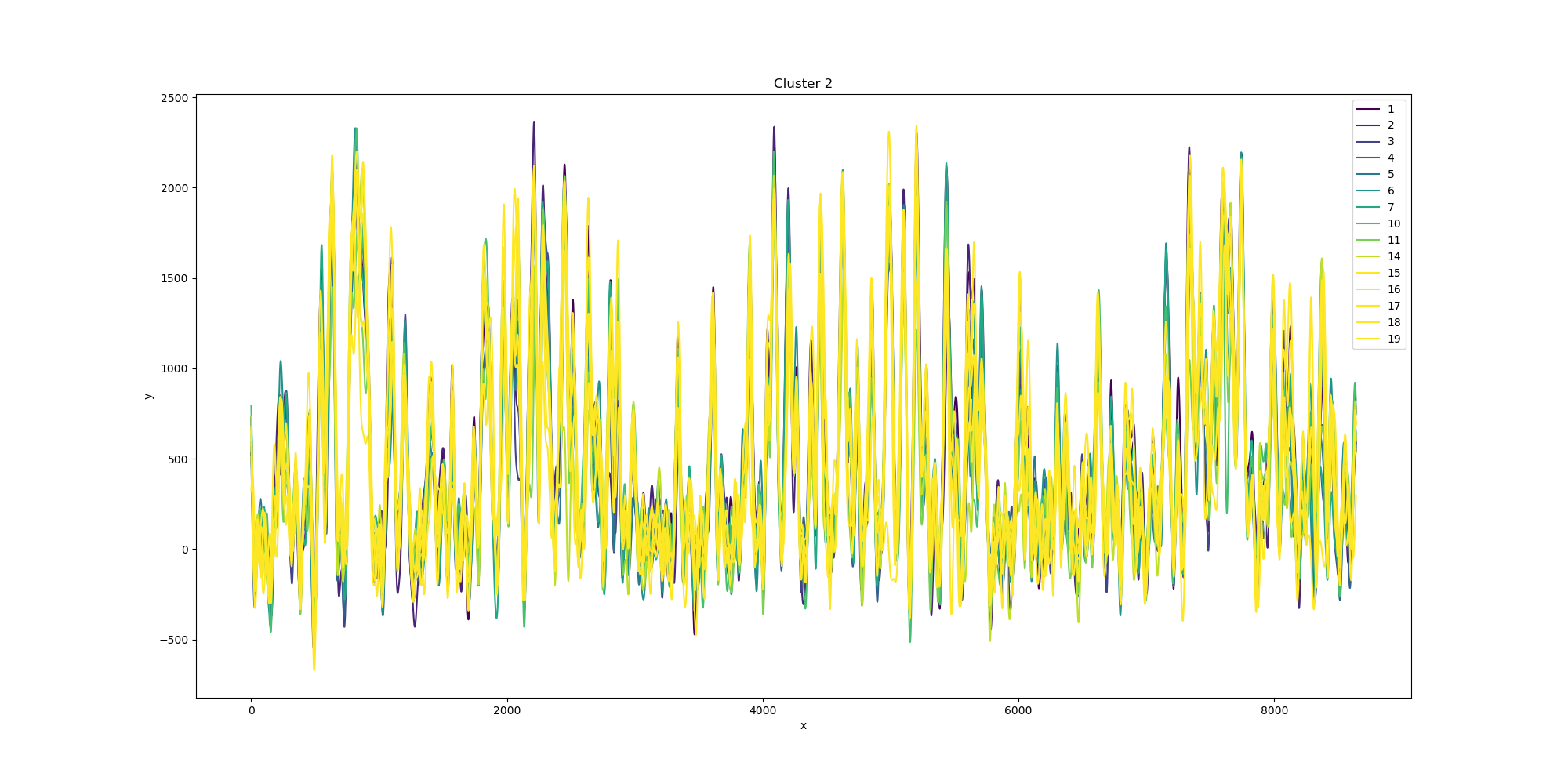
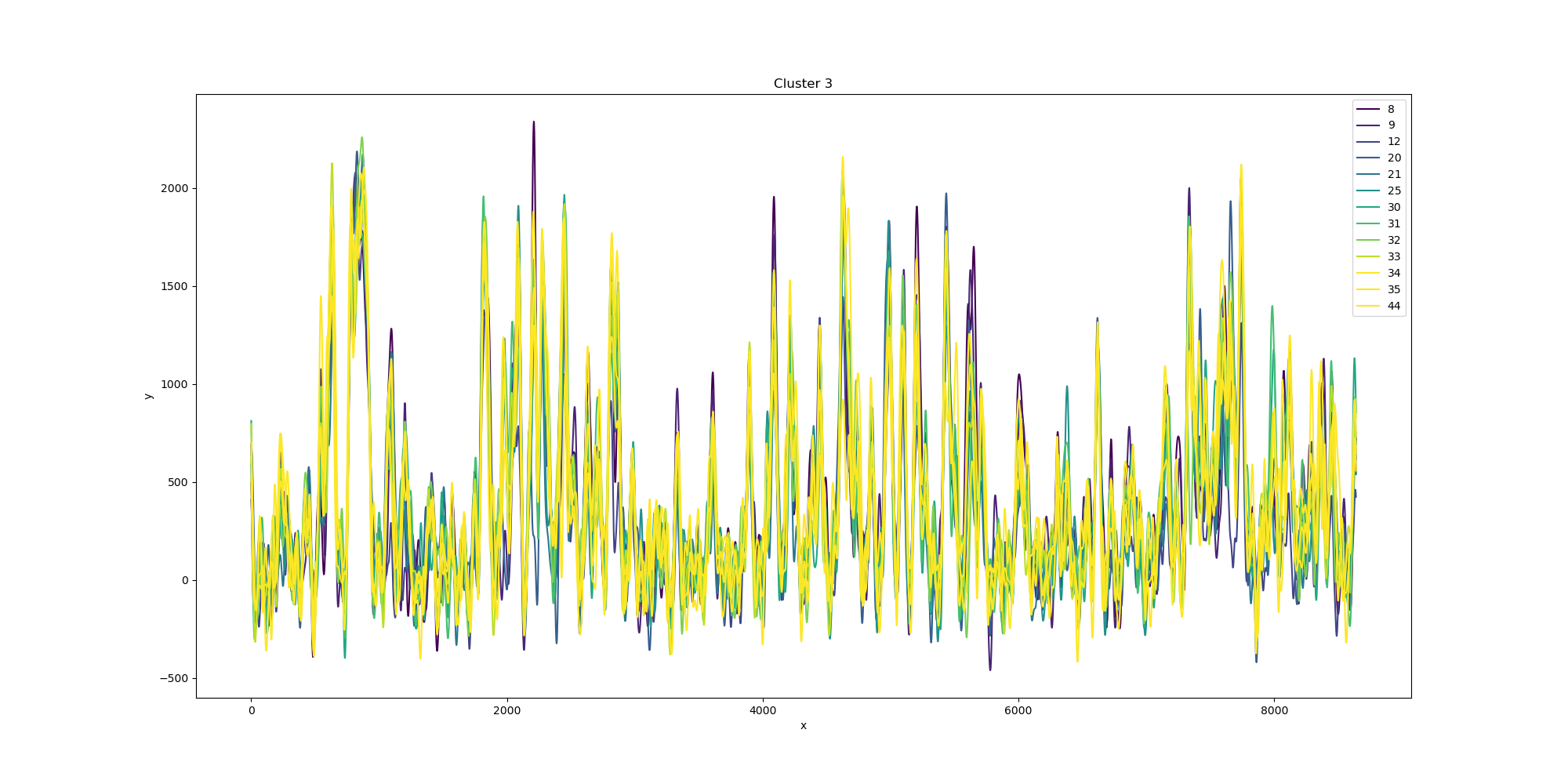
- def paint_turbine_k(self, k):
|
|
|
- """
|
|
|
- 绘制第k聚类的风机数据折线图
|
|
|
- :param k:
|
|
|
- :return:
|
|
|
- """
|
|
|
- pic_label = []
|
|
|
- y = []
|
|
|
- plt.figure(figsize=(20, 10))
|
|
|
- cmap = plt.get_cmap('viridis')
|
|
|
- for i, item in enumerate(self.cluster):
|
|
|
- if item == k:
|
|
|
- pic_label.append('turbine-' + str(self.turbine_id[i]))
|
|
|
- y.append(self.ori_turbine_fft[i])
|
|
|
- for i in range(len(y)):
|
|
|
- color = cmap(i / 10)
|
|
|
- plt.plot([j for j in range(len(y[i]))], y[i], color=color, label=pic_label[i])
|
|
|
- # 添加标签和标题
|
|
|
- plt.xlabel('x')
|
|
|
- plt.ylabel('y')
|
|
|
- plt.title('Cluster {}'.format(k))
|
|
|
-
|
|
|
- # 添加图例
|
|
|
- plt.legend()
|
|
|
- # 显示图形
|
|
|
- plt.savefig('analysis_img/cluster/cluster_{}.png'.format(k))
|
|
|
- plt.show()
|
|
|
-
|
|
|
- def turbine_fft(self, k):
|
|
|
- """
|
|
|
- 对第k台原始风机数据进行傅里叶变换,并绘制变换前后曲线
|
|
|
- :param k: 数据读入时的风机顺序index,从1开始
|
|
|
- :return: 傅里叶变换清洗后的数据,数据格式
|
|
|
- """
|
|
|
- y = self.ori_turbine_pic
|
|
|
- t = np.linspace(0, 1, self.data_length)
|
|
|
- signal = y[k - 1]
|
|
|
-
|
|
|
- # 进行傅里叶变换
|
|
|
- freq = np.fft.fftfreq(len(signal), t[1] - t[0])
|
|
|
- spectrum = np.fft.fft(signal)
|
|
|
- spectrum_abs = np.abs(spectrum)
|
|
|
- threshold = np.percentile(spectrum_abs, 98)
|
|
|
- indices = spectrum_abs > threshold
|
|
|
- spectrum_clean = indices * spectrum
|
|
|
-
|
|
|
- # 进行傅里叶逆变换
|
|
|
- signal_clean = np.fft.ifft(spectrum_clean)
|
|
|
- # plt.figure(figsize=(20, 10))
|
|
|
- #
|
|
|
- # # 绘制时域信号
|
|
|
- # plt.subplot(4, 1, 1)
|
|
|
- # plt.plot(t, signal)
|
|
|
- # plt.title(self.turbine_id[k-1])
|
|
|
- #
|
|
|
- # # 绘制频域信号
|
|
|
- # plt.subplot(4, 1, 2)
|
|
|
- # plt.plot(freq, np.abs(spectrum))
|
|
|
- #
|
|
|
- # # 绘制过滤后的频域信号
|
|
|
- # plt.subplot(4, 1, 3)
|
|
|
- # plt.plot(freq, np.abs(spectrum_clean))
|
|
|
- #
|
|
|
- # # 绘制过滤后的时域信号
|
|
|
- # plt.subplot(4, 1, 4)
|
|
|
- # plt.plot(t, signal_clean)
|
|
|
- #
|
|
|
- # plt.savefig('analysis_img/fft/{}_turbine_fft.png'.format(self.turbine_id[k-1]))
|
|
|
- # plt.show()
|
|
|
- return signal_clean
|
|
|
-
|
|
|
- def paint_double(self, i, j):
|
|
|
- """
|
|
|
- 绘制两台风机的数据变换对比
|
|
|
- :param i: 风机数据读入时数据编号,从1开始
|
|
|
- :param j: 风机数据读入时数据编号,从1开始
|
|
|
- :return:
|
|
|
- """
|
|
|
- y = self.ori_turbine_fft
|
|
|
- x = [index for index in range(self.data_length)]
|
|
|
- data_i = y[i - 1]
|
|
|
- data_j = y[j - 1]
|
|
|
-
|
|
|
- plt.figure(figsize=(20, 10))
|
|
|
- plt.plot(x, data_i, label='turbine {}'.format(self.turbine_id[i - 1]), linestyle='solid')
|
|
|
- plt.plot(x, data_j, label='turbine {}'.format(self.turbine_id[j - 1]), linestyle='dashed')
|
|
|
-
|
|
|
- plt.title('{} and {}'.format(i, j))
|
|
|
- plt.legend()
|
|
|
- plt.savefig('analysis_img/{}_{}_turbine.png'.format(self.turbine_id[i - 1], self.turbine_id[j - 1]))
|
|
|
- plt.show()
|
|
|
-
|
|
|
- def process_ori_data(self):
|
|
|
- """
|
|
|
- 对原始数据进行处理,聚类和绘图
|
|
|
- :return:
|
|
|
- """
|
|
|
- self.turbine_clusters(self.ori_turbine_fft)
|
|
|
- self.paint_turbine()
|
|
|
-
|
|
|
- def turbine_clusters(self, data=None):
|
|
|
- """
|
|
|
- 风机数据聚类,聚类信息保存在self.cluster中
|
|
|
- :param data: 默认为空,也可以使用其他数据聚类,并体现在绘图中,
|
|
|
- 数据格式:二维数据n*m,n为数据条数,m为每条数据维数
|
|
|
- :return: None
|
|
|
- """
|
|
|
- if data is None:
|
|
|
- cluster = hierarchical_clustering(self.turbine_diff, threshold=1.4,
|
|
|
- similarity_func=compute_pearsonr) # 层次聚类
|
|
|
- else:
|
|
|
- cluster = hierarchical_clustering(data, threshold=0.8,
|
|
|
- similarity_func=compute_pearsonr)
|
|
|
- self.cluster = cluster
|
|
|
- # 在这里保存cluster变量
|
|
|
- from cluster_analysis import cluster_power_list_file, cluster_power_list_folder
|
|
|
-
|
|
|
- output_path = '../data-process/data/cluster_power/'
|
|
|
-
|
|
|
- cluster_power_list_file(self.cluster, self.turbine_id,
|
|
|
- input_path='../data-process/data/output_filtered_csv_files/', output_path=output_path)
|
|
|
- cluster_power_list_folder(self.cluster, self.turbine_id, input_path='../data-process/data/continuous_data/',
|
|
|
- output_path=output_path)
|
|
|
-
|
|
|
-
|
|
|
-data_analysis = DataAnalysis(data_length=9773,
|
|
|
- data_start=0,
|
|
|
- data_end=9773)
|
|
|
-
|
|
|
-data_analysis.process_ori_data()
|
|
|
-data_analysis.paint_double(1, 56)
|

 liudawei
liudawei
{kind=link}
{kind=link}
{kind=link}
{kind=link}

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}