liudawei
liudawei
81 módosított fájl, 3457 hozzáadás és 0 törlés
+ 3
- 0
.gitignore
|
||
|
||
|
||
|
||
+ 6
- 0
README.md
|
||
|
||
|
||
|
||
|
||
|
||
|
||
A különbségek nem kerülnek megjelenítésre, a fájl túl nagy
+ 884
- 0
light-fcm-clustering/Fuzzy-C-Means/.ipynb_checkpoints/Fuzzy C-Means develop-checkpoint.ipynb
+ 14
- 0
light-fcm-clustering/Fuzzy-C-Means/FCM.md
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
A különbségek nem kerülnek megjelenítésre, a fájl túl nagy
+ 884
- 0
light-fcm-clustering/Fuzzy-C-Means/Fuzzy C-Means develop.ipynb
+ 188
- 0
light-fcm-clustering/Fuzzy-C-Means/PlotFunctions.py
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
+ 300
- 0
light-fcm-clustering/Fuzzy-C-Means/fuzzy_c_means.py
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
+ 151
- 0
light-fcm-clustering/Fuzzy-C-Means/iris_data.csv
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
BIN
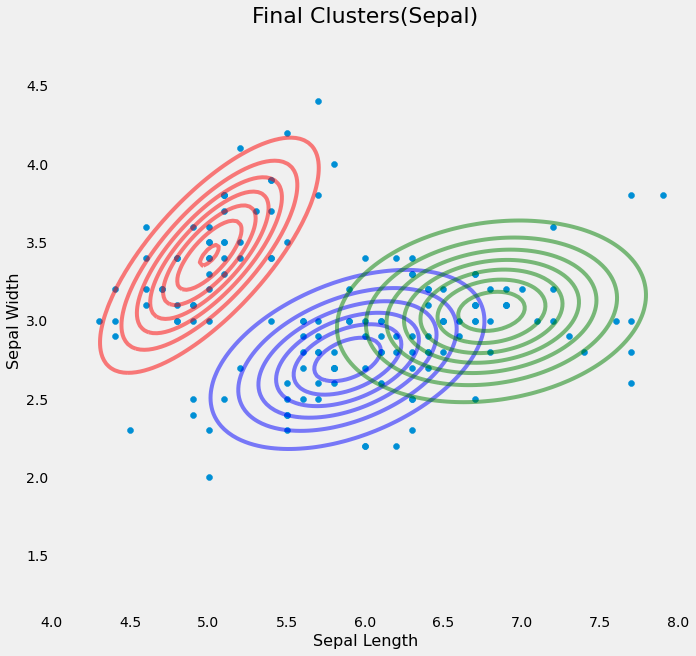
light-fcm-clustering/Fuzzy-C-Means/results/final_clusters.png
{kind=link}
BIN
light-fcm-clustering/Fuzzy-C-Means/results/final_clusters2.png
{kind=link}
BIN
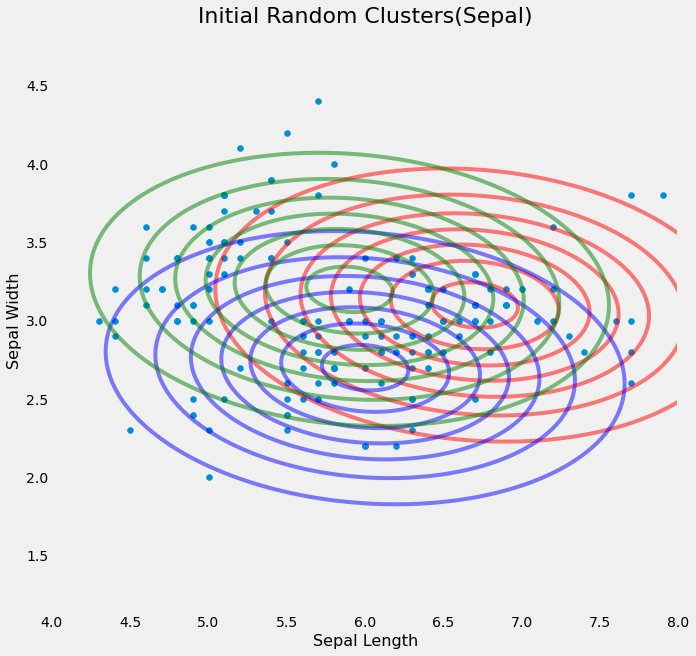
light-fcm-clustering/Fuzzy-C-Means/results/initial_random.png
{kind=link}
BIN
light-fcm-clustering/Fuzzy-C-Means/results/initial_random2.png
{kind=link}

BIN
light-fcm-clustering/Fuzzy-C-Means/results/notes1.PNG
{kind=link}

BIN
light-fcm-clustering/Fuzzy-C-Means/results/notes2.PNG
{kind=link}

BIN
light-fcm-clustering/Fuzzy-C-Means/results/notes3.PNG
{kind=link}

+ 82
- 0
light-fcm-clustering/env_data.py
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
+ 44
- 0
light-fcm-clustering/visual.py
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
+ 14
- 0
wind-fft-clustering/.gitignore
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
+ 6
- 0
wind-fft-clustering/README.md
|
||
|
||
|
||
|
||
|
||
|
||
|
||
+ 110
- 0
wind-fft-clustering/cluster_analysis.py
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
+ 163
- 0
wind-fft-clustering/data_add.py
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
+ 483
- 0
wind-fft-clustering/data_analysis.py
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
+ 78
- 0
wind-fft-clustering/data_clean.py
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
+ 21
- 0
wind-fft-clustering/聚类结果说明/README.md
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
+ 11
- 0
wind-fft-clustering/聚类结果说明/cluster/README.md
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
BIN
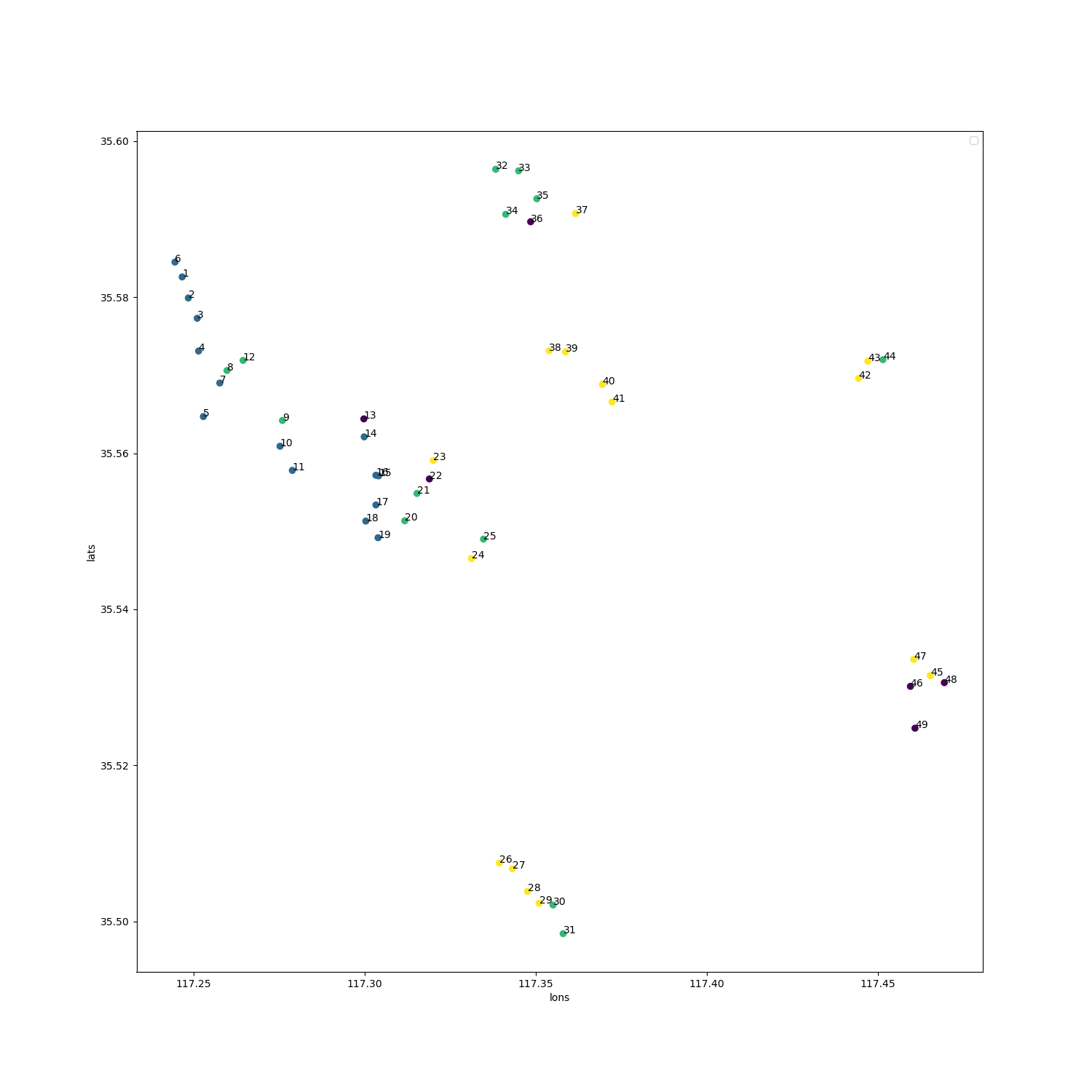
wind-fft-clustering/聚类结果说明/cluster/cluster_1.png
{kind=link}
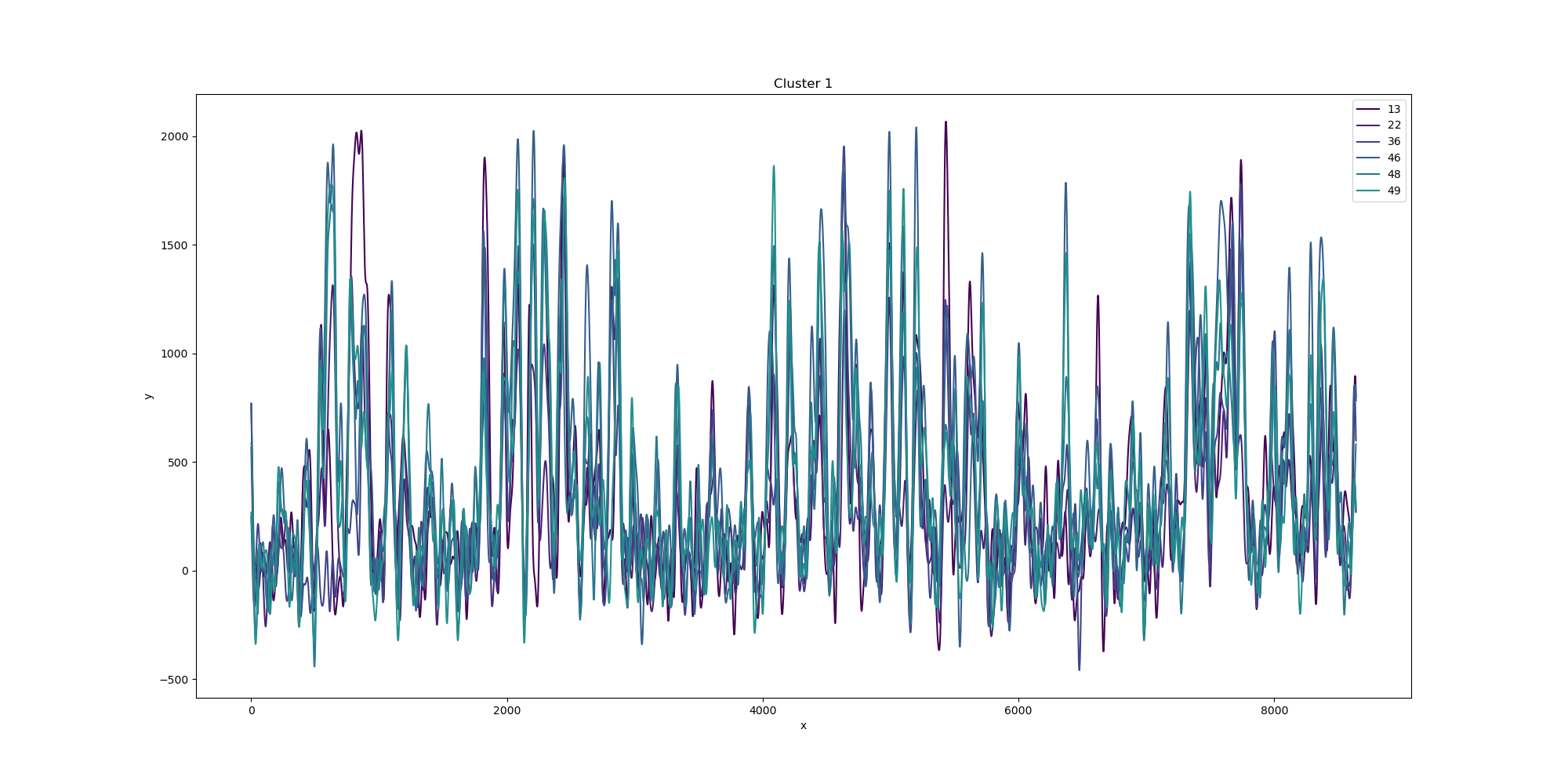
BIN
wind-fft-clustering/聚类结果说明/cluster/cluster_2.png
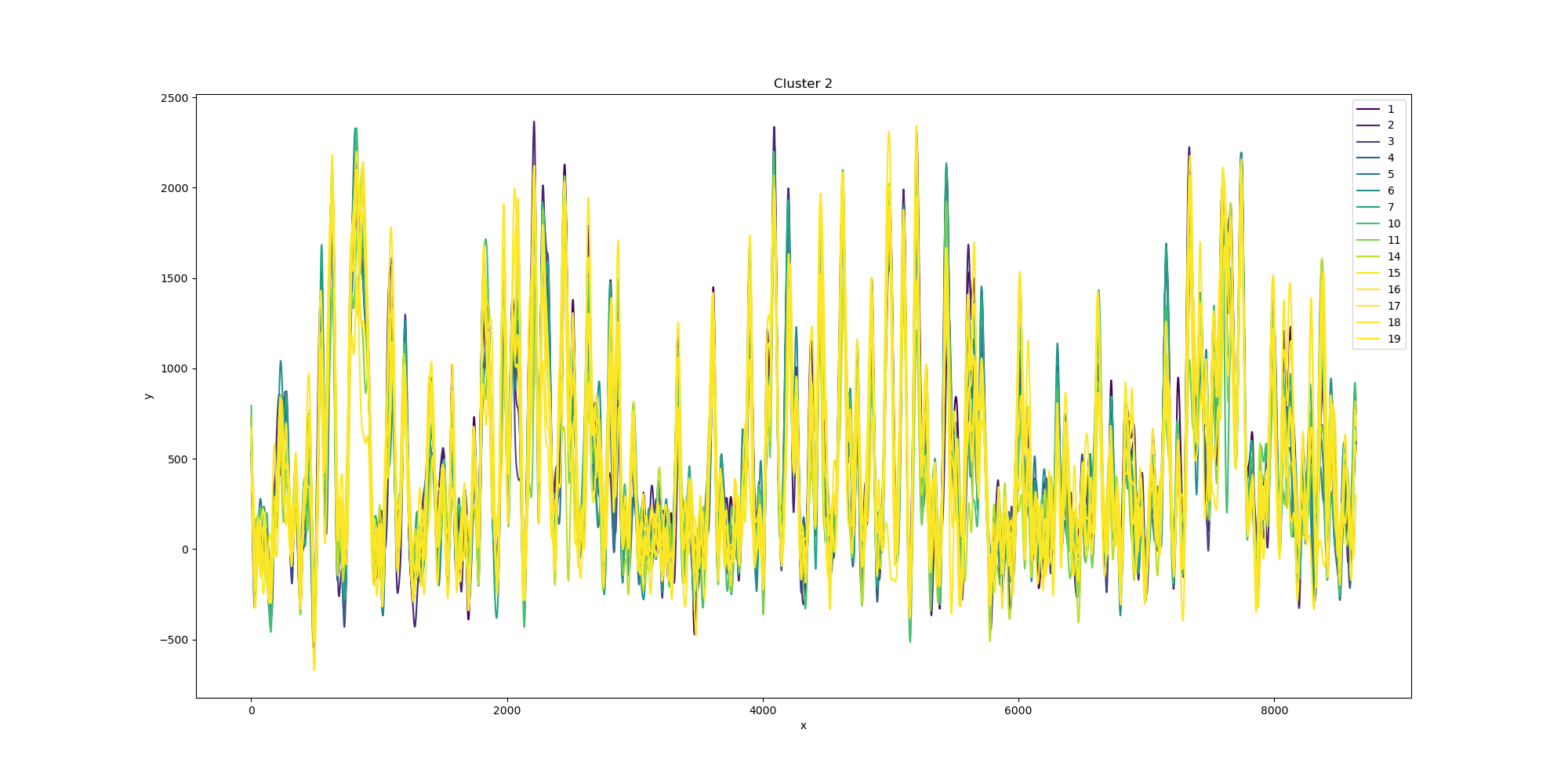
{kind=link}
BIN
wind-fft-clustering/聚类结果说明/cluster/cluster_3.png
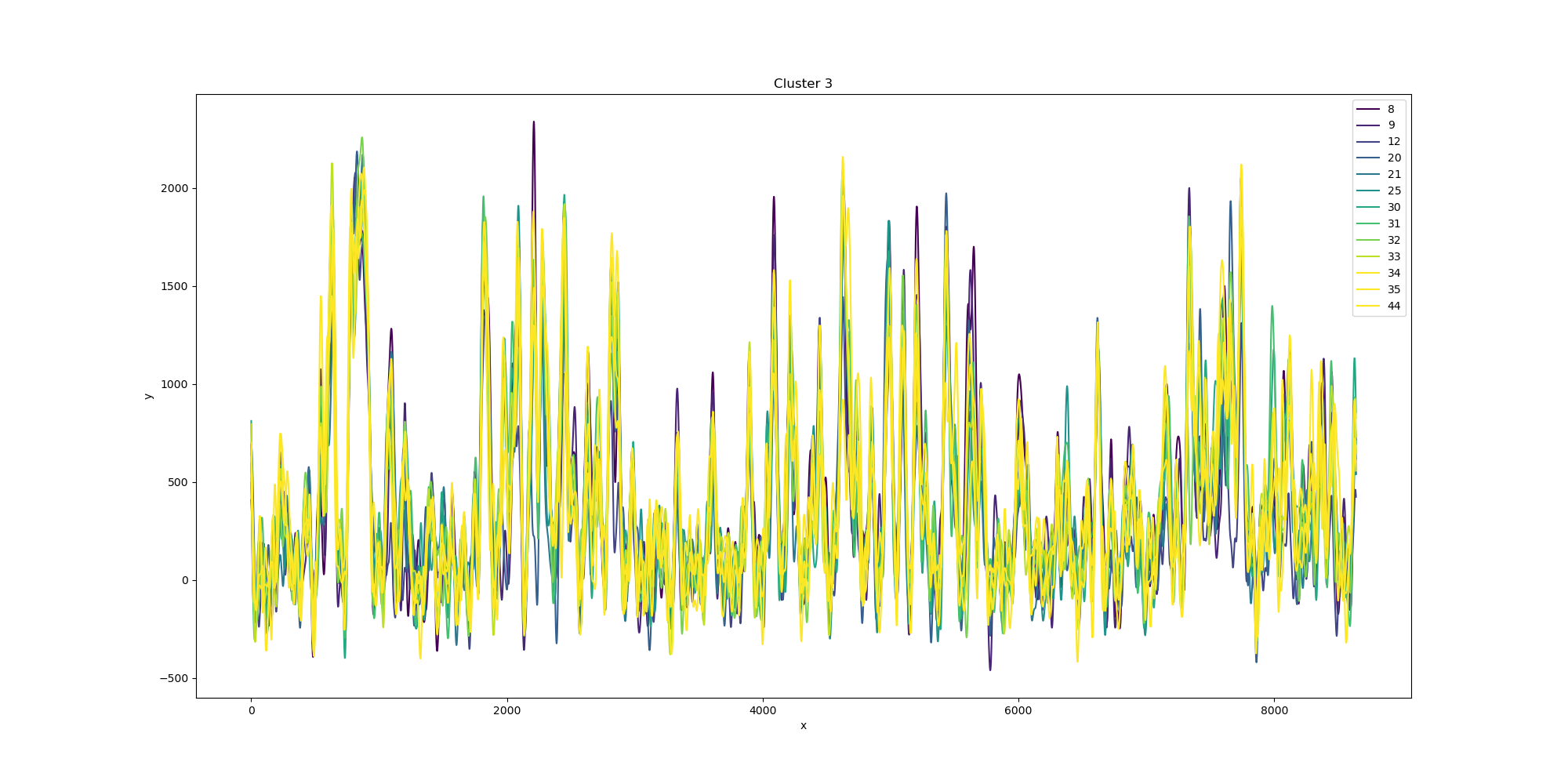
{kind=link}
BIN
wind-fft-clustering/聚类结果说明/cluster/cluster_4.png
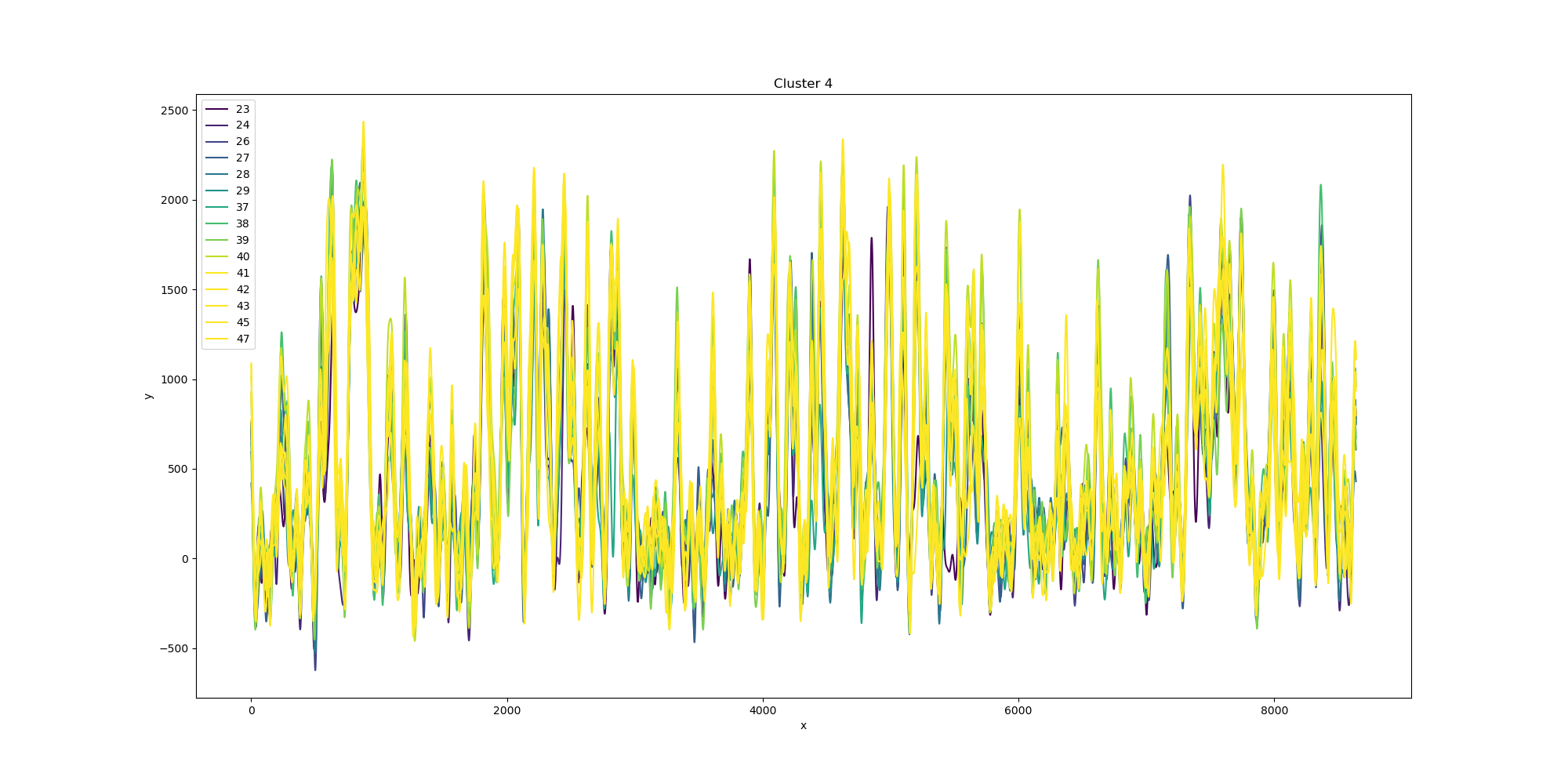
{kind=link}
BIN
wind-fft-clustering/聚类结果说明/fft/10_turbine_fft.png
{kind=link}
BIN
wind-fft-clustering/聚类结果说明/fft/11_turbine_fft.png
{kind=link}
BIN
wind-fft-clustering/聚类结果说明/fft/12_turbine_fft.png
{kind=link}
BIN
wind-fft-clustering/聚类结果说明/fft/13_turbine_fft.png
{kind=link}
BIN
wind-fft-clustering/聚类结果说明/fft/14_turbine_fft.png
{kind=link}
BIN
wind-fft-clustering/聚类结果说明/fft/15_turbine_fft.png
{kind=link}
BIN
wind-fft-clustering/聚类结果说明/fft/16_turbine_fft.png
{kind=link}
BIN
wind-fft-clustering/聚类结果说明/fft/17_turbine_fft.png
{kind=link}
BIN
wind-fft-clustering/聚类结果说明/fft/18_turbine_fft.png
{kind=link}
BIN
wind-fft-clustering/聚类结果说明/fft/19_turbine_fft.png
{kind=link}
BIN
wind-fft-clustering/聚类结果说明/fft/1_turbine_fft.png
{kind=link}
BIN
wind-fft-clustering/聚类结果说明/fft/20_turbine_fft.png
{kind=link}
BIN
wind-fft-clustering/聚类结果说明/fft/21_turbine_fft.png
{kind=link}
BIN
wind-fft-clustering/聚类结果说明/fft/22_turbine_fft.png
{kind=link}

BIN
wind-fft-clustering/聚类结果说明/fft/23_turbine_fft.png
{kind=link}
BIN
wind-fft-clustering/聚类结果说明/fft/24_turbine_fft.png
{kind=link}
BIN
wind-fft-clustering/聚类结果说明/fft/25_turbine_fft.png
{kind=link}
BIN
wind-fft-clustering/聚类结果说明/fft/26_turbine_fft.png
{kind=link}
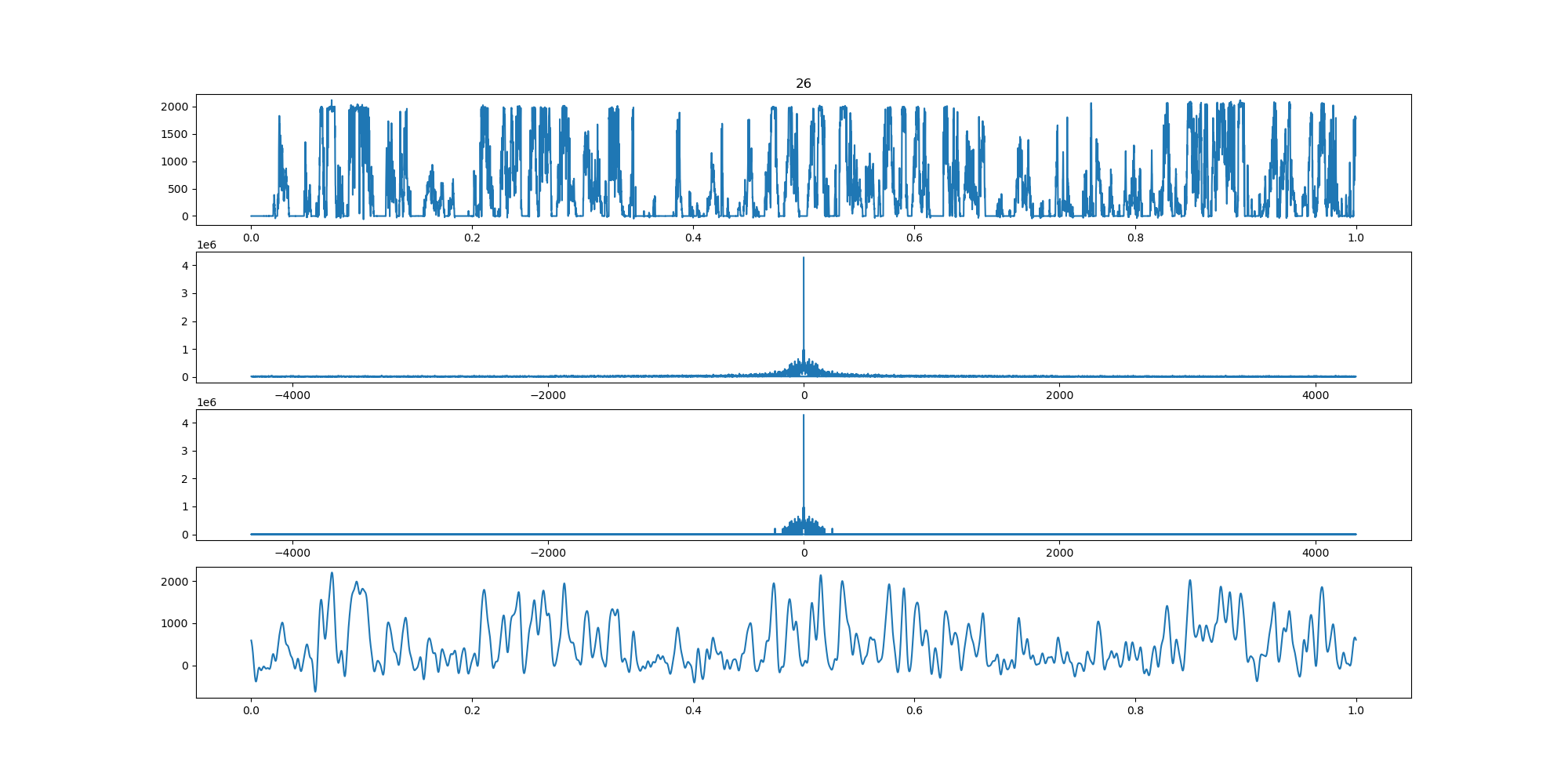
BIN
wind-fft-clustering/聚类结果说明/fft/27_turbine_fft.png
{kind=link}
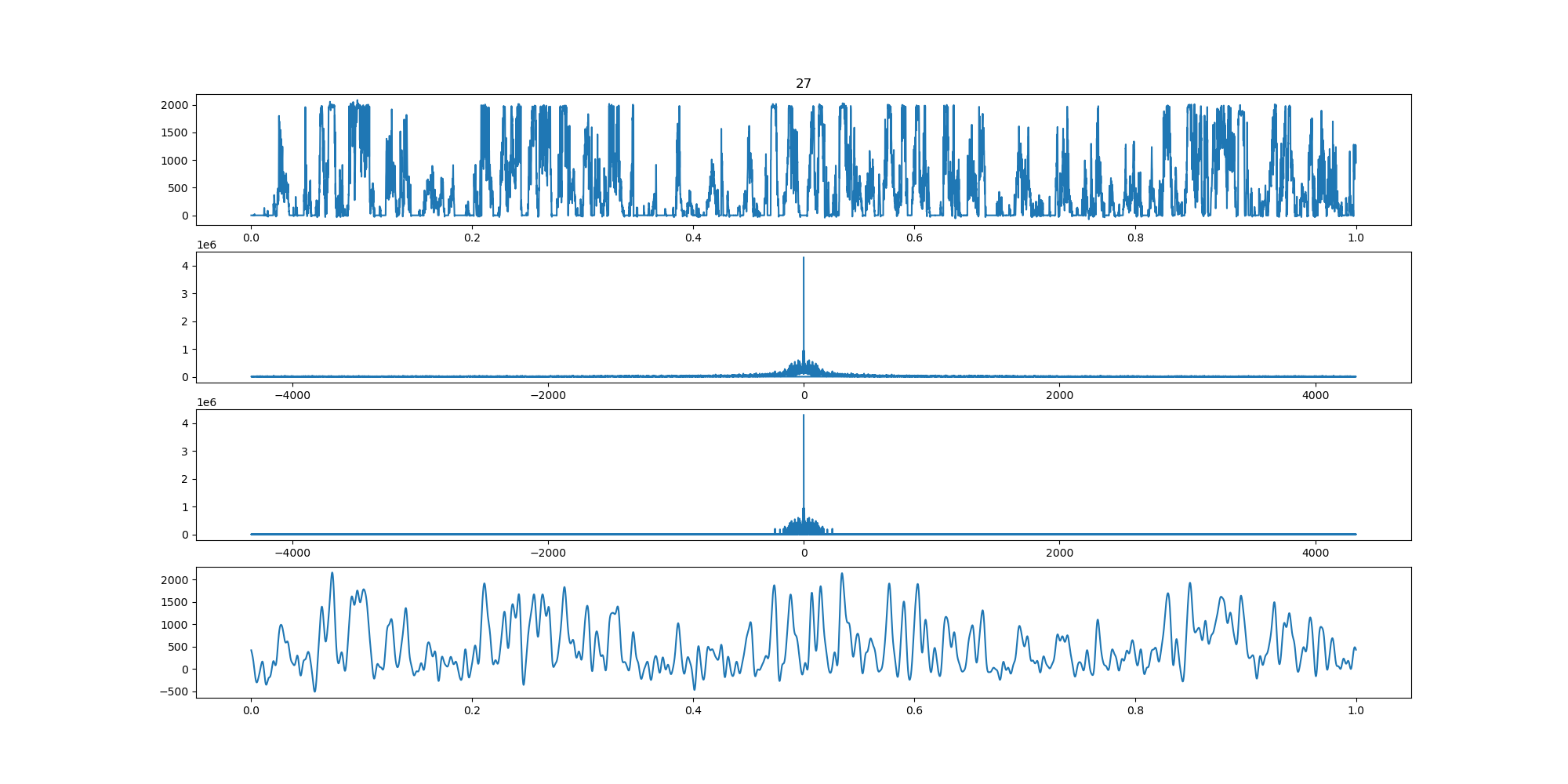
BIN
wind-fft-clustering/聚类结果说明/fft/28_turbine_fft.png
{kind=link}
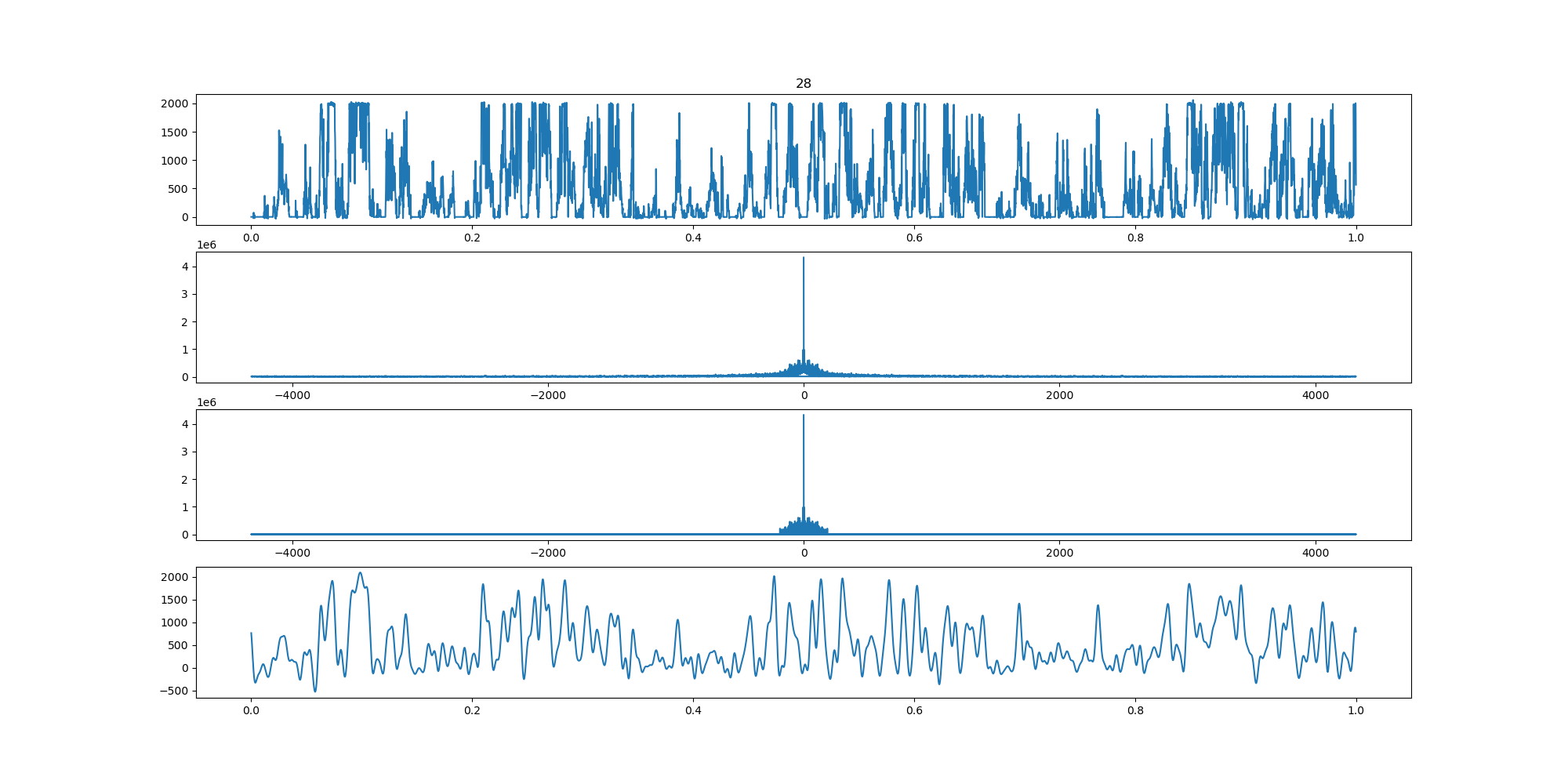
BIN
wind-fft-clustering/聚类结果说明/fft/29_turbine_fft.png
{kind=link}
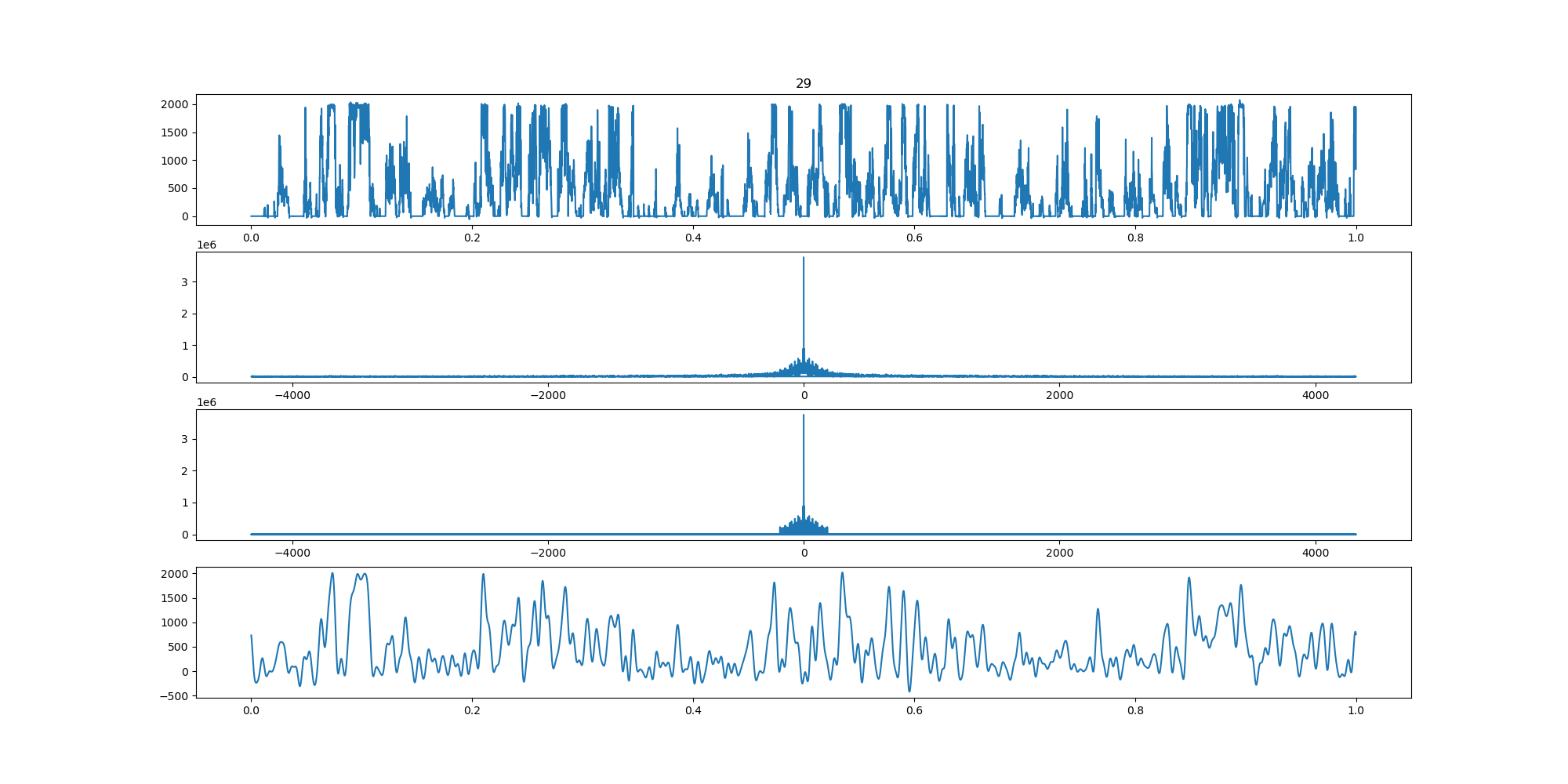
BIN
wind-fft-clustering/聚类结果说明/fft/2_turbine_fft.png
{kind=link}
BIN
wind-fft-clustering/聚类结果说明/fft/30_turbine_fft.png
{kind=link}
BIN
wind-fft-clustering/聚类结果说明/fft/31_turbine_fft.png
{kind=link}
BIN
wind-fft-clustering/聚类结果说明/fft/32_turbine_fft.png
{kind=link}

BIN
wind-fft-clustering/聚类结果说明/fft/33_turbine_fft.png
{kind=link}
BIN
wind-fft-clustering/聚类结果说明/fft/34_turbine_fft.png
{kind=link}
BIN
wind-fft-clustering/聚类结果说明/fft/35_turbine_fft.png
{kind=link}
BIN
wind-fft-clustering/聚类结果说明/fft/36_turbine_fft.png
{kind=link}
BIN
wind-fft-clustering/聚类结果说明/fft/37_turbine_fft.png
{kind=link}
BIN
wind-fft-clustering/聚类结果说明/fft/38_turbine_fft.png
{kind=link}
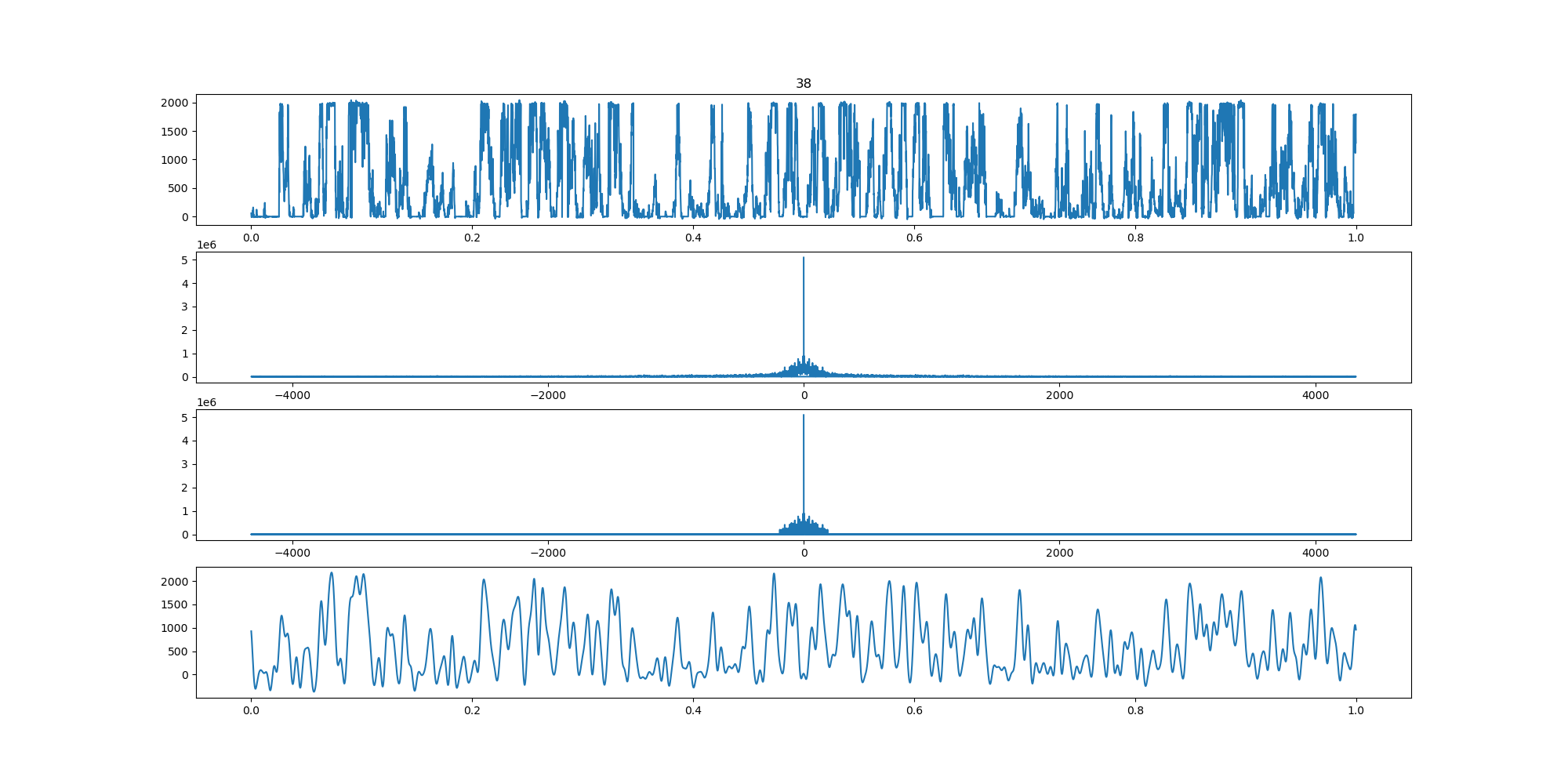
BIN
wind-fft-clustering/聚类结果说明/fft/39_turbine_fft.png
{kind=link}
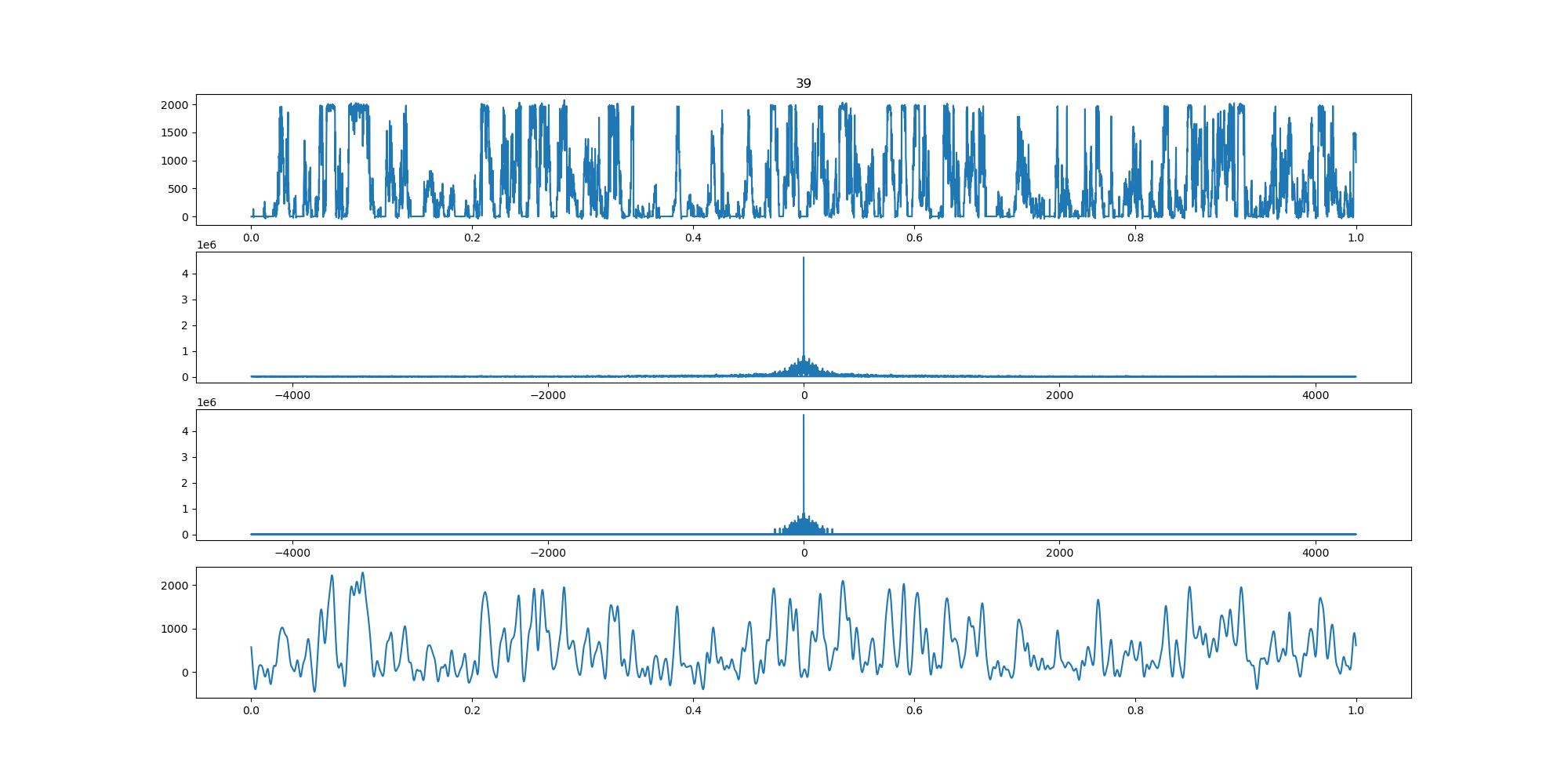
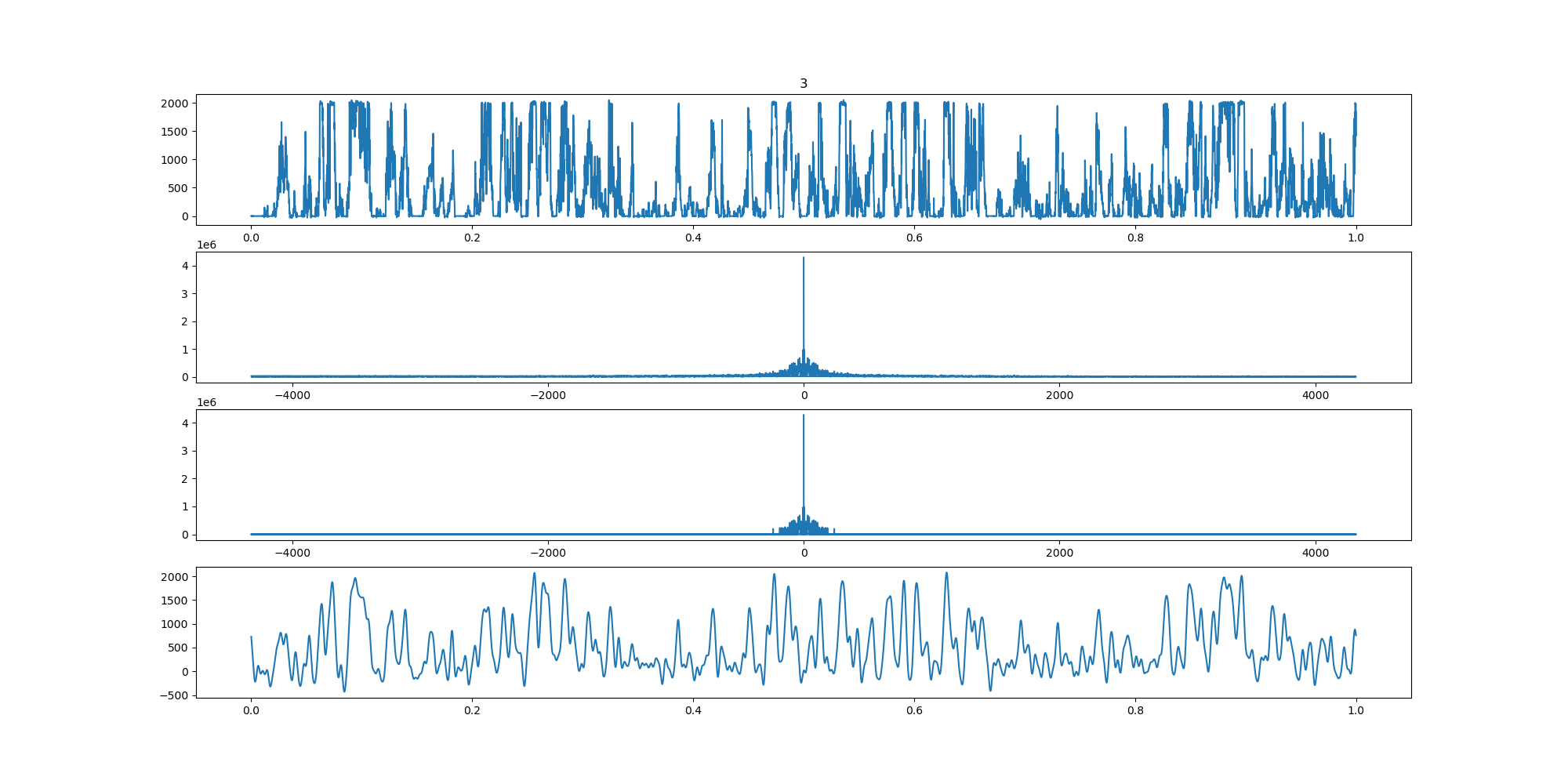
BIN
wind-fft-clustering/聚类结果说明/fft/3_turbine_fft.png
{kind=link}
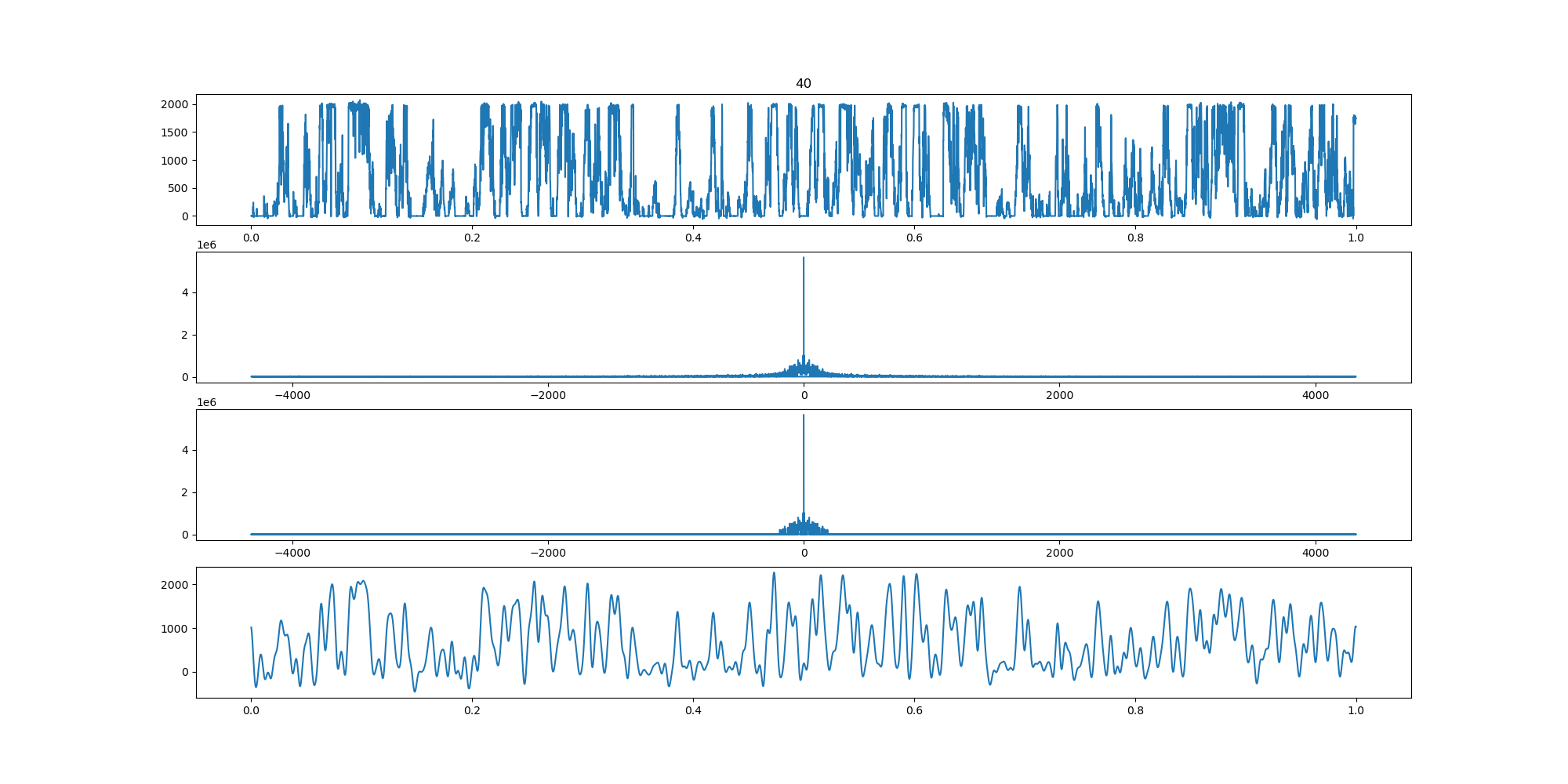
BIN
wind-fft-clustering/聚类结果说明/fft/40_turbine_fft.png
{kind=link}
BIN
wind-fft-clustering/聚类结果说明/fft/41_turbine_fft.png
{kind=link}
BIN
wind-fft-clustering/聚类结果说明/fft/42_turbine_fft.png
{kind=link}
BIN
wind-fft-clustering/聚类结果说明/fft/43_turbine_fft.png
{kind=link}
BIN
wind-fft-clustering/聚类结果说明/fft/44_turbine_fft.png
{kind=link}
BIN
wind-fft-clustering/聚类结果说明/fft/45_turbine_fft.png
{kind=link}
BIN
wind-fft-clustering/聚类结果说明/fft/46_turbine_fft.png
{kind=link}
BIN
wind-fft-clustering/聚类结果说明/fft/47_turbine_fft.png
{kind=link}
BIN
wind-fft-clustering/聚类结果说明/fft/48_turbine_fft.png
{kind=link}
BIN
wind-fft-clustering/聚类结果说明/fft/49_turbine_fft.png
{kind=link}
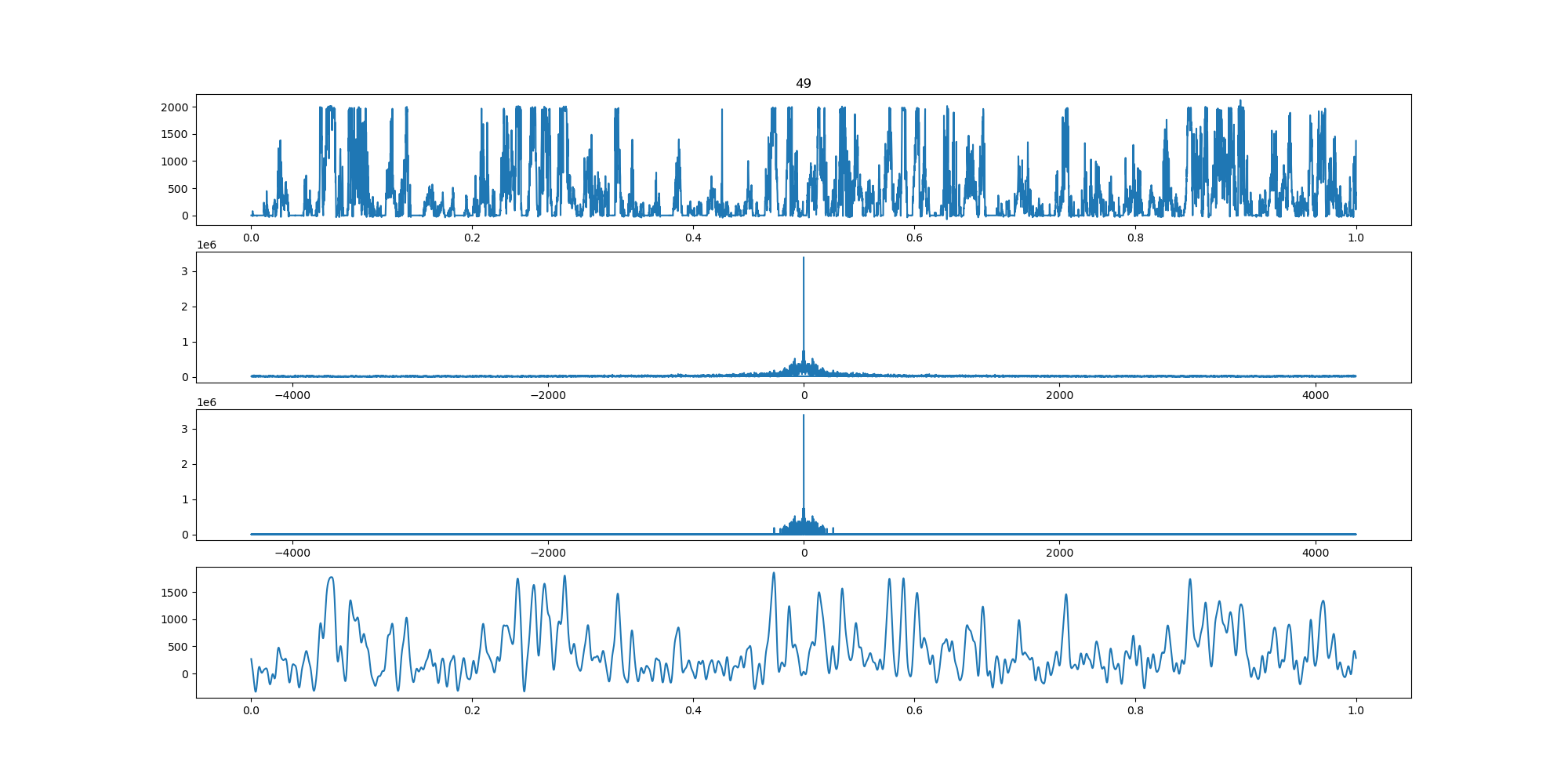
BIN
wind-fft-clustering/聚类结果说明/fft/4_turbine_fft.png
{kind=link}
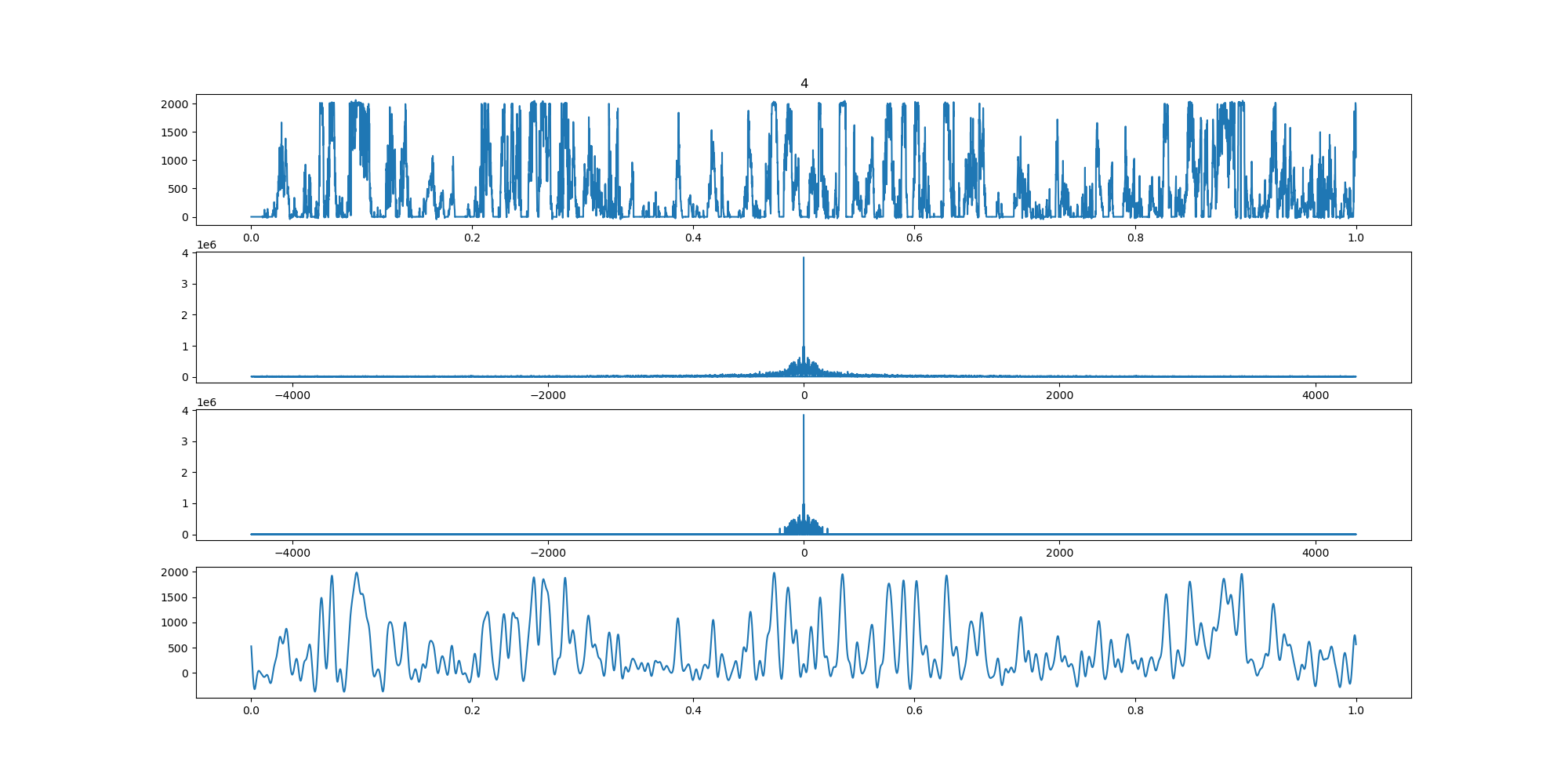
BIN
wind-fft-clustering/聚类结果说明/fft/5_turbine_fft.png
{kind=link}
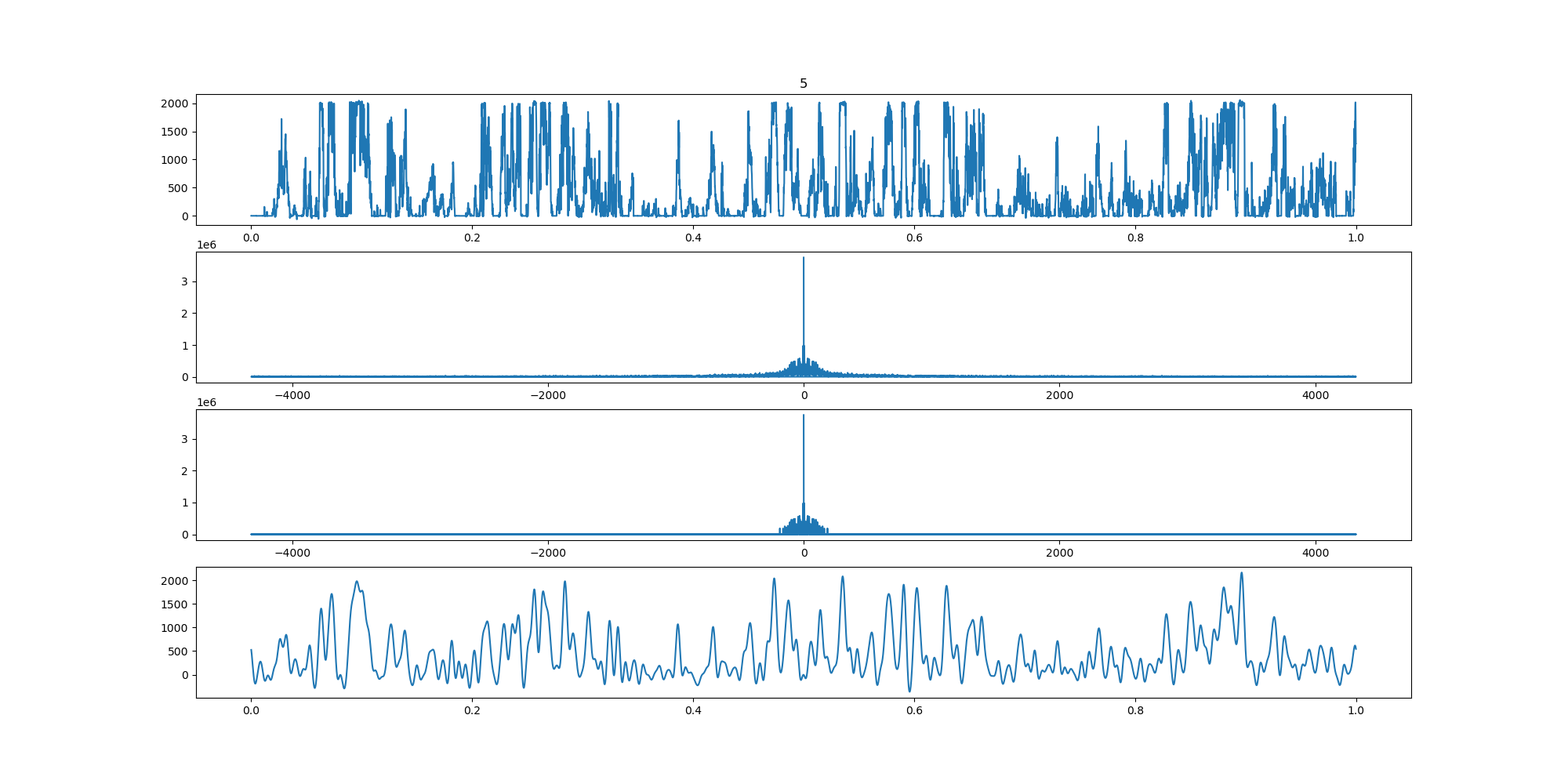
BIN
wind-fft-clustering/聚类结果说明/fft/6_turbine_fft.png
{kind=link}
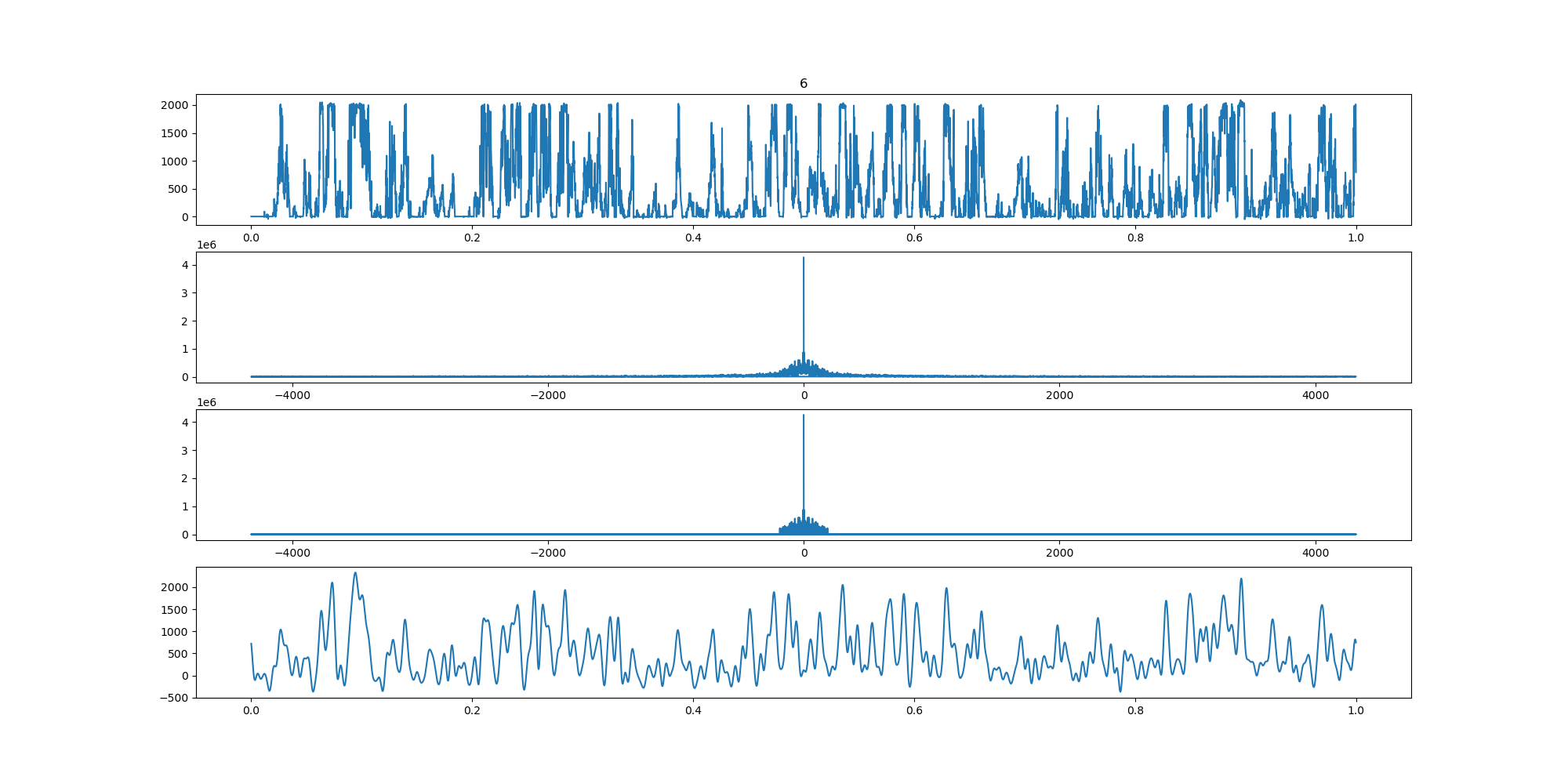
BIN
wind-fft-clustering/聚类结果说明/fft/7_turbine_fft.png
{kind=link}
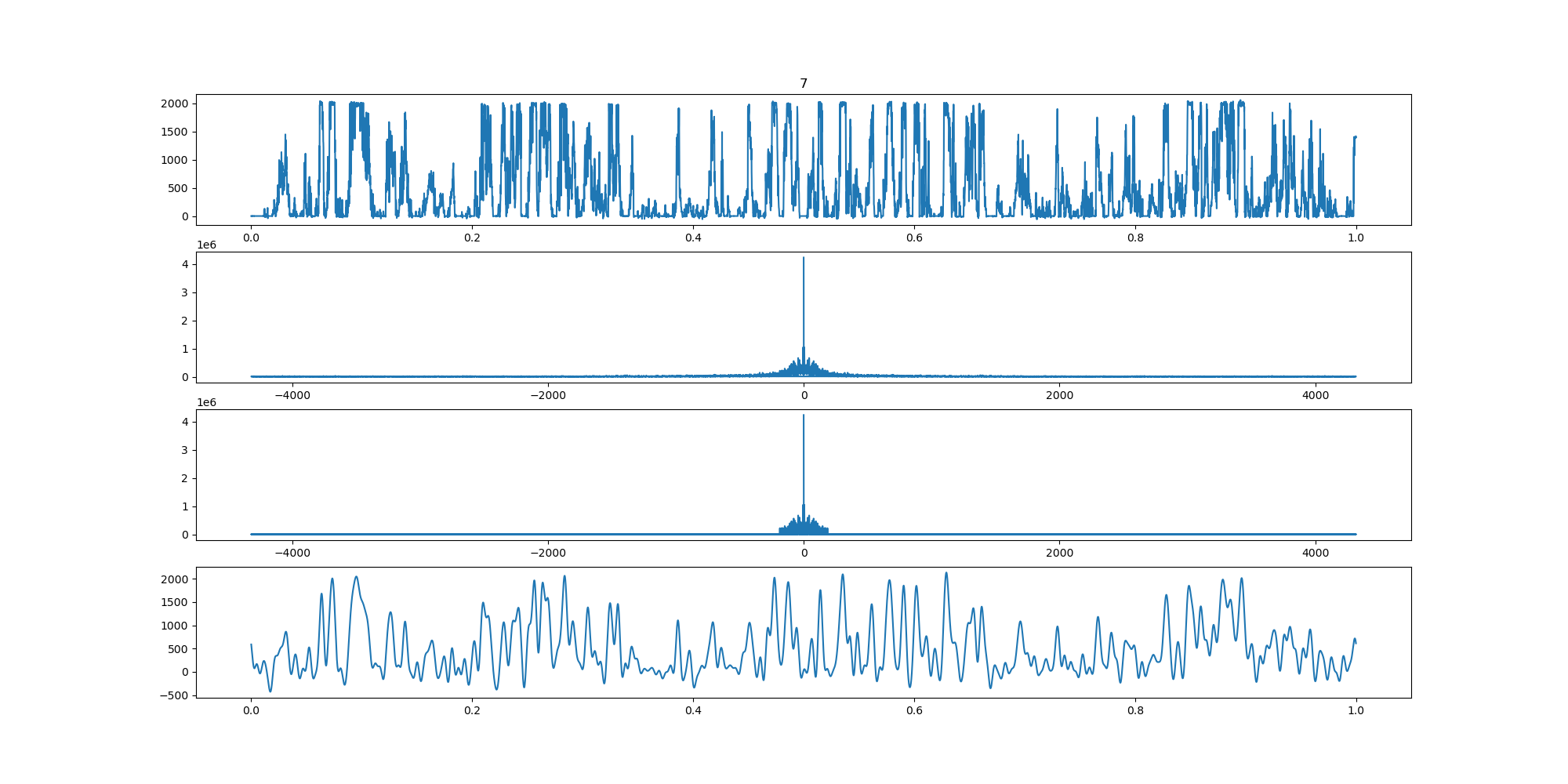
BIN
wind-fft-clustering/聚类结果说明/fft/8_turbine_fft.png
{kind=link}
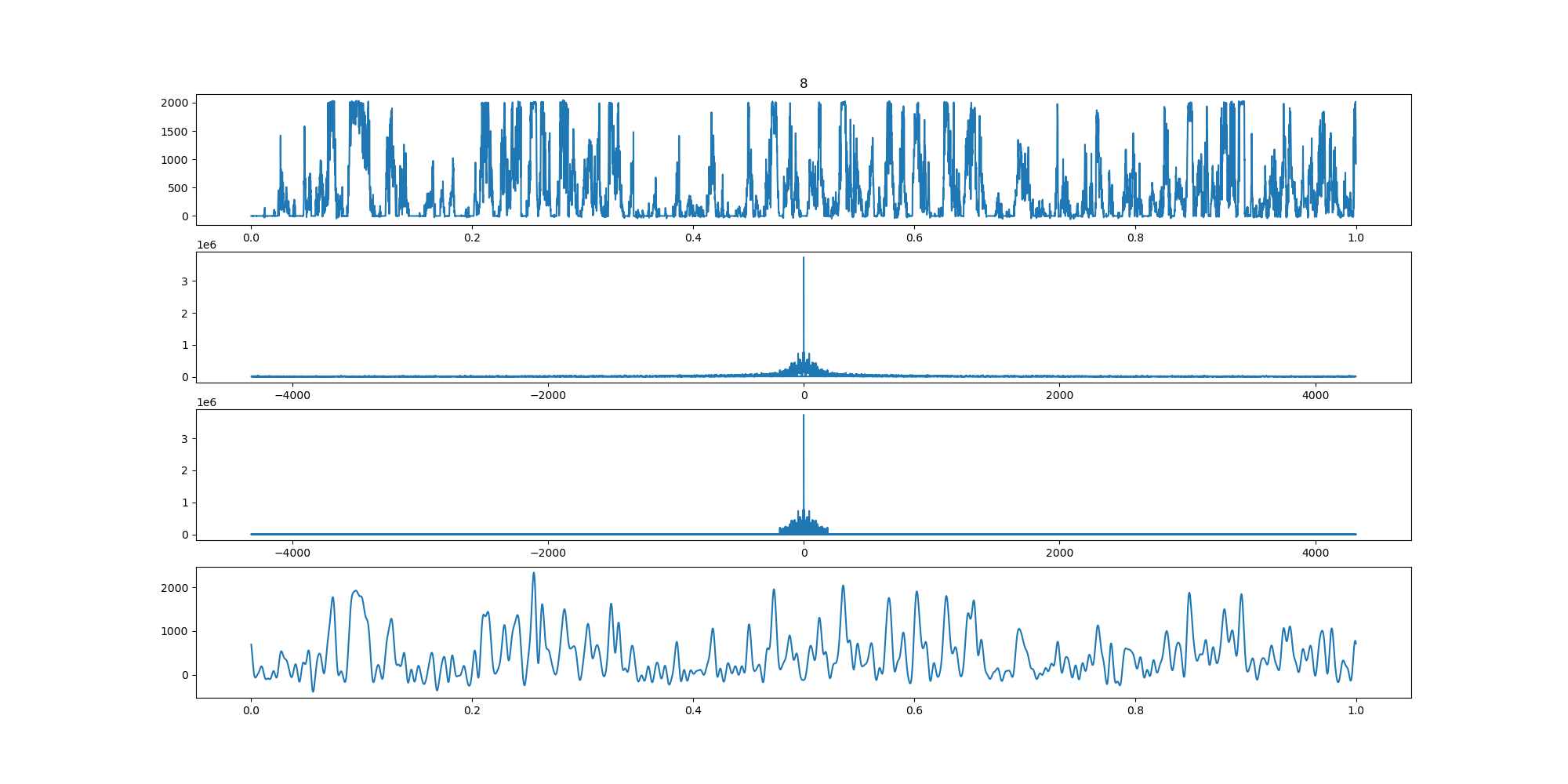
BIN
wind-fft-clustering/聚类结果说明/fft/9_turbine_fft.png
{kind=link}
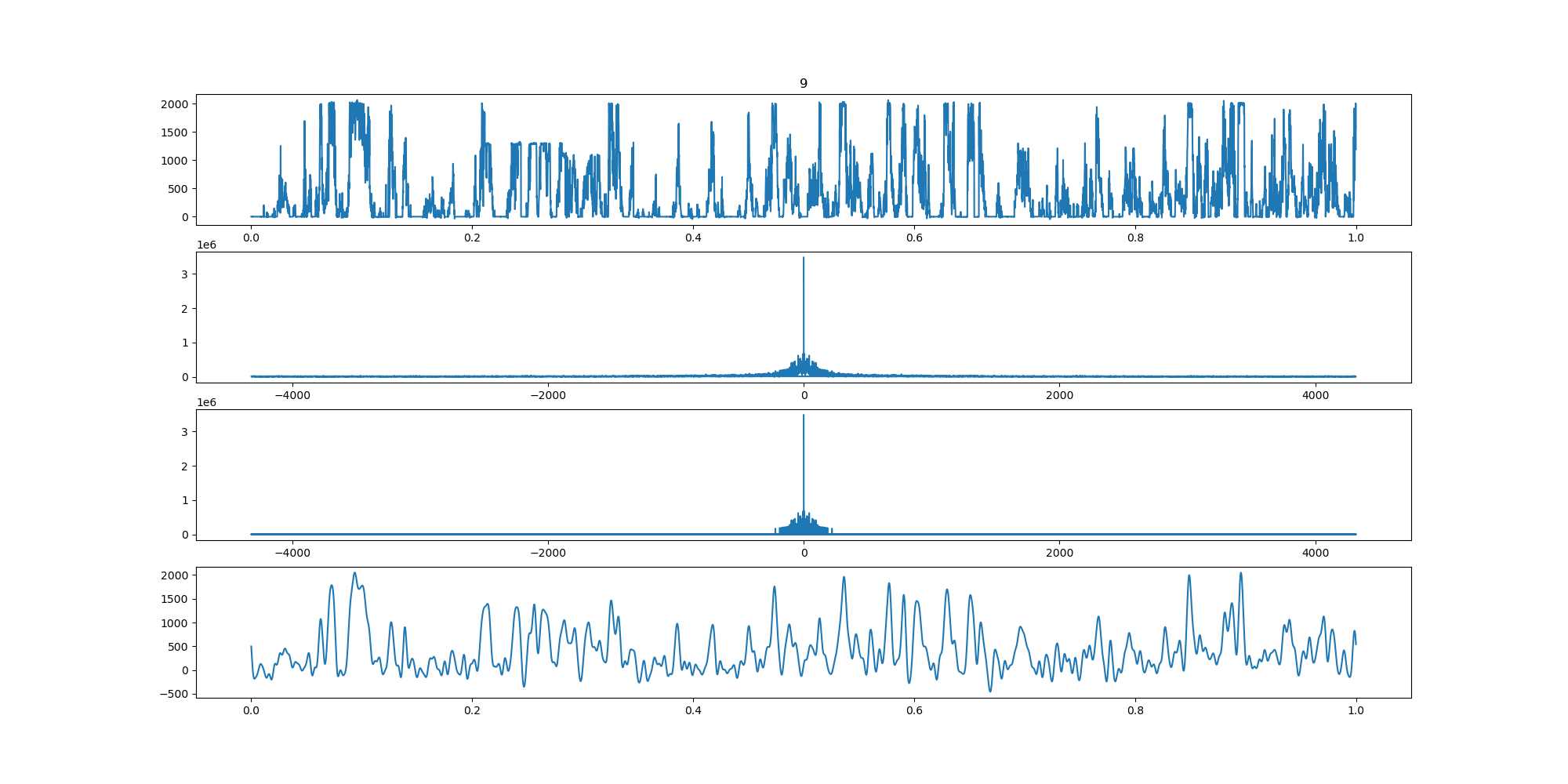
+ 15
- 0
wind-fft-clustering/聚类结果说明/fft/README.md
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
BIN
wind-fft-clustering/聚类结果说明/turbine_cluster.png
{kind=link}